
# C++
# 零、碎
# 1. 选择 判断 知识点
1. 逻辑运算符两侧运算对象的数据类型可以是任何类型的数据
2. if (!x) 等价于 if (x==0||x=='0');
3. x = ++y ++x =y 是正确的 (x+y)++ 是错误的
4. 条件编译允许在编译时包含不同的代码
5.C++ 中,cin 是预定义的对象
6. 使用提取符 (<<) 可以输出各种基本数据类型的变量的值,也可以输出指针值。
7. 和指针类似,引用被初始化后,还可以引用别的变量。❌
8. 以下程序中,new 语句干了什么。
int** num;
num = new int* [20];分配了长度为 20 的整数指针数组空间,并将 num [0] 的指针返回。
9.c++ 中不允许嵌套函数(在一个函数中定义新函数)
10. 抽象类只能作为基类来使用,其纯虚函数的实现由派生类给出;
11. 类的非静态成员函数才有 this 指针
12. 因为静态成员函数不能是虚函数,所以它们不能实现多态。
13. int i; int &ri=i; 对于这条语句,ri 和 i 这两个变量代表的是同一个存储空间。 (引用)
14. 构造函数可以被重载,析构函数不可以被重载。因为构造函数可以有多个且可以带参数,而析构函数只能有一个,且不能带参数。
15. 如果基类声明了带有形参表的构造函数,则派生类就应当声明构造函数
16. 基类中的私有成员不论通过何种派生方式,到了派生类中均变成不可直接访问成员。
17. 纯虚函数与函数体为空的虚函数等价。❌
18. 不可以对数组类型进行整体赋值
19. 函数可以返回一个不带索引的数组名
20.<img src="https://cdn.jsdelivr.net/gh/rainnn-w/Pictures@main/blog/202308281108760.png" alt="image-20230615162748030" />(B)
21.<img src="https://cdn.jsdelivr.net/gh/rainnn-w/Pictures@main/blog/202308281108577.png" alt="image-20230615171122503" />(B)
22. 指向函数的指针变量 p 可以先后指向不同的同种类型的函数,但不可作加减运算。
23. 数组名就是数组的起始地址,数组的指针就是数组的起始地址。
24. 用指针变量作函数参数,可以得到多个变化了的值。
25. 成员函数是公有的,在内存中存在一份,各个对象都可以使用
# 2. 读程序 计算
(1)
//若
#define N 3
#define Y(n) ((N+1)*n)
//则
z=2*(N+Y(5+1))//z值为48
(2)负数对正数取余结果为负数,正数对负数取余结果为正数
-7%5=-2;
7%-5=2;
-7%-5=-2;(3)运算符优先级
int x=3,y=4,z;
z=x++==4 || ++y==5;
cout<<y<<z;51
int a=0;
cout << (a=4+5,a+5),a+25;
cout << ((a=4+5,a+5),a+25);
cout << (a=3*5,a*4),a+15;
cout << ((a=3*5,a*4),a+15);14346030
运算符优先级:括号运算 > 加法 > 赋值 > 逗号
(4)条件运算符
int a = 1, b = 2, c = 3, d = 4;
int answer = a < b ? a : b < c ? b : c < d ? c : d;
cout << answer;1
条件运算符的结合性是从右到左结合的,先算 c<d?c:d 返回 c=3;再算 a<b?a:c 返回值为 1。
(5)注意细节!
//执行以下的程序片段,将输出几个数字?
for(i=0;i<3;i++);
cout<<i;1 个数字,for 循环没有方法体
输出:2
(6) bool
bool flag = 2021;//flag 1
cout << (flag > 2019) + flag * 2 + bool(4) << endl; //输出结果为3(7)string
char s[5];
cin.getline(s,4); //只读入3位(会存'\0')
int n = strlen(s);
cout << s << " ";
cout << n << " ";
cout << sizeof(s) << " ";
char* q="abcde";
q+=2;
cout<<q; //cde输入:ABCDE
输出:ABC 3 5
(8)5 4 6

# 指针阅读程序
int a[] = {1,2,3,4,5};
int *p; //a[0]
p = a+1; //a[1]
cout << a << endl; //地址
cout << &a << endl; //与a相同 地址
//cout << a++ << endl; //Error
cout << &a+1 << endl; //下一位地址
cout << *(a+1) << endl; //2
cout << *p << p[1] << a[1] << endl;//232
cout << *p++ << endl; //2 a[2]
(*p)++; // a[2]++ 即a[2]=4
cout << p << endl; //输出地址
cout << *p << endl; //4
cout << *(a+2); //4 此时a[2]已经等于4//指针数组
int a[]={1,3,5,7,9};
int *p[]={a,a+1,a+2,a+3,a+4};
cout << a[4] << endl; //9
cout << &a[4] << endl; //地址 0x61fe10
cout << p[4] << endl; //同上地址 0x61fe10
cout << *p[4] << endl; //9
cout << &p[4] << endl; //地址 0x61fdf0
cout << *(a+4) << endl;//9
cout << *(p+4) << endl; //地址 0x61fe10
cout << **(p+4) << endl; //9
cout << *(p+4)-*(p+0) << endl; //4 运算顺序(
cout << (*(p+4)-*(p+0)) << endl; //4
cout << *(a+3)%a[4] << endl; //7 (7%9)//数组指针
int (*p)[5];
int a[5]={1,3,5,7,9};
cout << p << endl; //地址0x10
cout << a << endl; //地址0x61fe00
cout << p[2] << endl; //地址0x38
cout << *p << endl; //地址0x10
cout << a+2 << endl; //地址0x61fe08
cout << *(a+2) << endl; //5
cout << p++ << endl; //地址0x10
cout << *p++ << endl; //地址0x24
cout << *p << endl; //0x38# 派生类构造函数
1. 调用基类构造函数,对基类数据成员初始化;
2. 调用子对象构造函数,对子对象数据成员初始化;
3. 再执行派生类构造函数本身,对派生类数据成员初始化。
#include <iostream>
using namespace std;
class A{
public: A(int aa){cout<< aa;};
};
class B:public A{
int b; A a;// 子对象a
public:
B(int bb):a(bb-2),A(bb+1),b(bb+2){
b = bb-4;
cout << b <<endl;
}
};
int main(){ A a(3); B b(4); }
//3520C++ 声明 + 赋值一个对象指针时,调用默认构造函数。如果只是声明,那 么不会调用构造函数,分配空间给 p,但是不可用。
默认构造函数(即无参构造函数)不一定存在,但是拷贝构造函数总是会存在。
# 一、概述
# (一)程序设计语言
# 1. 低级语言
机器语言(采用指令编码和数据的存储地址来表示指令的操作以及操作数)
可以直接在计算机上执行
汇编语言(用符号来表示指令的操作以及操作数)
必须翻译成机器语言才能执行(翻译工作由程序 assembler 汇编程序 来自动完成)
# 2. 高级语言
# (二)c++ 程序的构成
1. 每个 c++ 程序必须有且仅有一个名字为 main 的全局函数,称为主函数,程序从全局函数 main 开始执行,main 函数的返回值类型为 int
一般情况下,返回 0 表示程序正常结束,返回负数(如 - 1)表示程序非正常结束
2. 一个 c++ 程序可以存放在一个或多个文件(称为源文件)中,每个源文件包含一些程序实体的定义,其中有且仅有一个源文件中包含全局函数 main
# (三)词法
1. 标识符
标识符命名规则:
- 由 ** 大小写中英文字母、数字、下划线、美元符号($)** 构成
- 第一个字符不能是数字
- 标识符通常用作程序实体的名字
- 大小写字母有区别
(C++ 语言保留了一些名字供语言本身使用,这些名字不能被用作标识符。)
2. 关键字
3. 字面常量
4. 操作符
5. 标点符号
注释不构成可执行程序的一部分
不参加编译,也不会出现在目标程序中
预处理和函数头后面不需要加
;表示结束#include <iostream>续行符
\(将一个单词分成多行来写,需在每行最后加续行符)
# (四)cpp 程序的运行
- 编写 C++ 程序一般需经过的几个步骤依次是:编辑、编译、连接、运行
- 程序执行的顺序:本程序文件的 main 函数开始,到 main 函数结束
- 源程序的扩展名:
.cpp/.h - 目标文件:
.obj - 可执行文件:
.exe
# (五)进制转换
十进制整数 ---- 二进制 / 八进制 / 十六进制:除以 2/8/16 从下往上取余
十进制小数 ---- 二进制 / 八进制 / 十六进制:乘以 2/8/16 从上往下取整

- 二进制 / 八进制 / 十六进制 ---- 十进制:

- 二进制 ---- 八进制 / 十六进制:
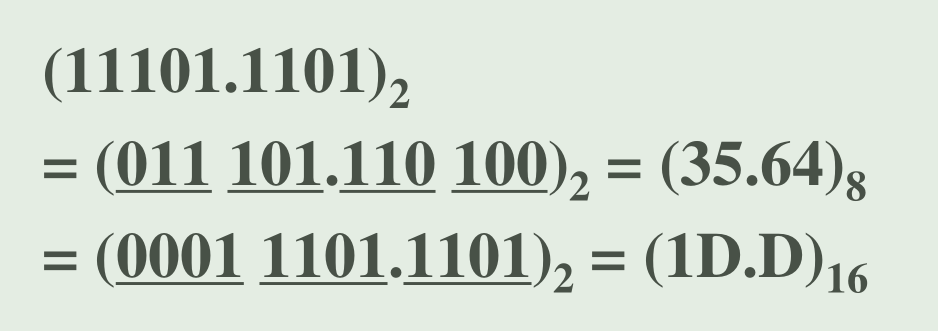
# (六)原码 反码 补码
- 原码:2 进制表示 (通常最高位表示正负 1 负 0 正)
对于 n 个二进制位构成的原码,能表示的整数范围为 -(2(n-1)-1)~2(n-1)-1
- 补码:
- 正整数:原码
- 负整数:原码各位取反后加 1
对于 n 个二进制位构成的补码,能表示的整数范围为 -2(n-1)~2(n-1)-1
<img src="https://cdn.jsdelivr.net/gh/rainnn-w/Pictures@main/blog/202308281109118.png" alt="image-20230615162922367" style="zoom:33%;" />(A)
- 加减法
- 加:补码直接相加,舍去最高位
- 减:减数取负,与被减数相加,舍去最高位
# 二、基本数据类型和表达式
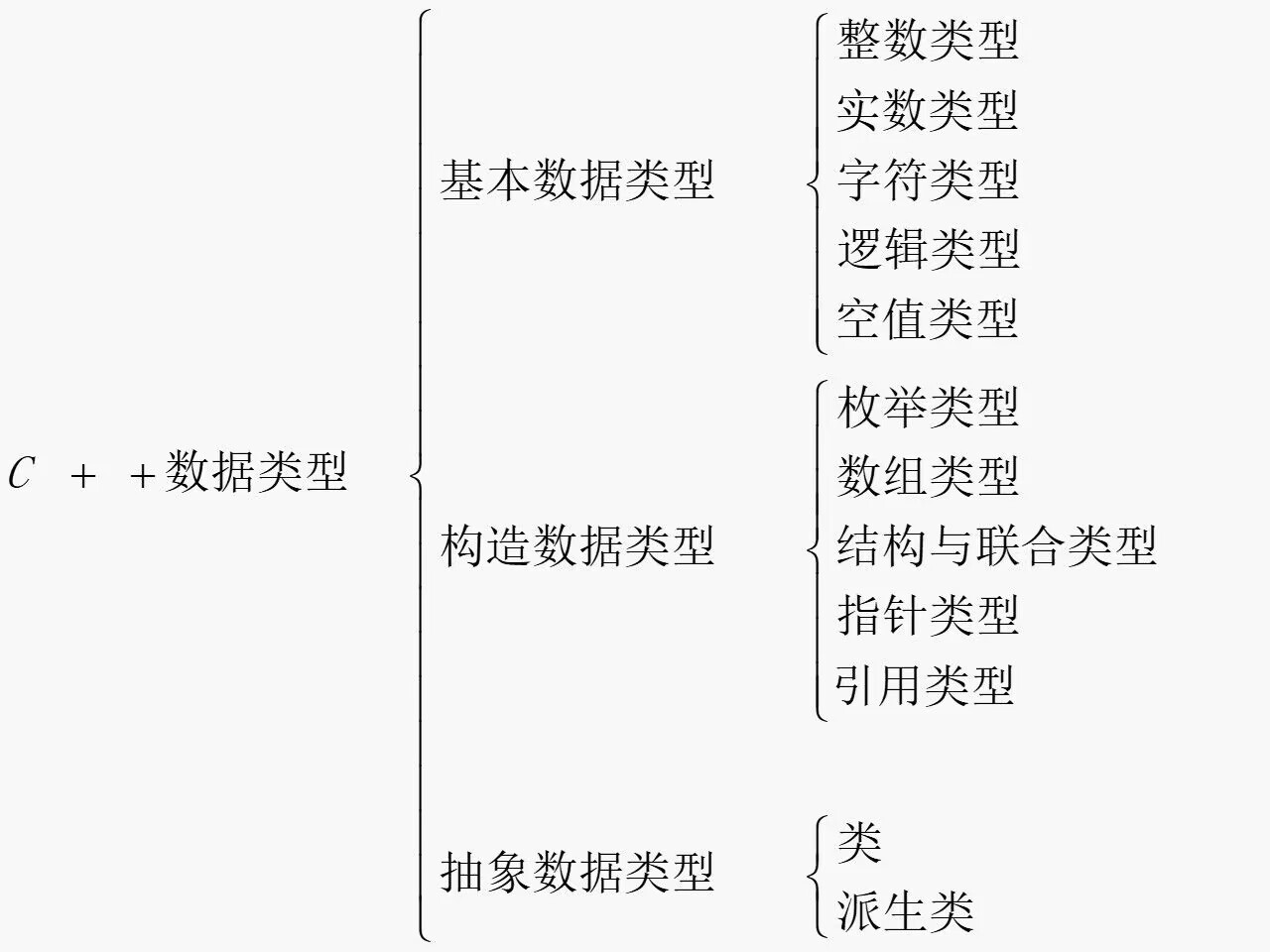
# (一)基本数据类型

可以使用
sizeof(<类型>)或sizeof(<变量>)运算其字节长度
# 1. 整数类型
int2/4 字节 (由计算机字长决定)short intshort2 字节long intlong4 字节无符号整数类型
unsigned int/unsignedunsigned short int/unsigned shortunsigned long int/unsigned long
无符号整数类型所占内存大小与相应整数类型相同
有符号整数类型的数,分配给其内存空间中会占用一个二进制位表示它的符号
但无符号整数类型其内存空间中没有表示符号的位
# 2. 实数类型(浮点类型)默认为 double
float4 个字节double8 个字节long double8/10 个字节
# 3. 字符类型
char1 个字节wchar_t
ASCII 字符集:a--97 A--65
# 4. 逻辑类型 bool
- 1 真 true
- 0 假 false
# 5. 空值类型
voidvoid*通用指针类型
# (二)表现形式
# 1. 常量
字面常量 在程序中直接写出常量值的常量
整数类型常量
- 十进制 第一个数字不能是 0(0 除外)
- 八进制 由 0 开头
- 十六进制 由 0x 或 0X 开头
实数类型常量
- 小数:可以省略小数点前后的 0
5..5 - 科学计数法:
4.2E2= 4.2*10^2
- 小数:可以省略小数点前后的 0
字符类型常量
'A'\101(八进制)\x41(十六进制)'\n’(换行符)‘\r’(回车符)‘\t’(横向制表符)‘\b’(退格符)‘\a’(响铃)'\f'(换页,在打印机上,屏幕上没有页)
字符串常量 为一维字符数组
符号常量 有名字的常量
const double PI=3.14;#define PI 3.14(
#define定义的标识符在编译前将被替换成所定义的内容)
# 2. 变量
变量有一定的生存周期和作用范围
int a=5;
int a(5);
- 定义
- 赋值:对内存空间初始化
- 使用:获取,或者改变内存空间的数值
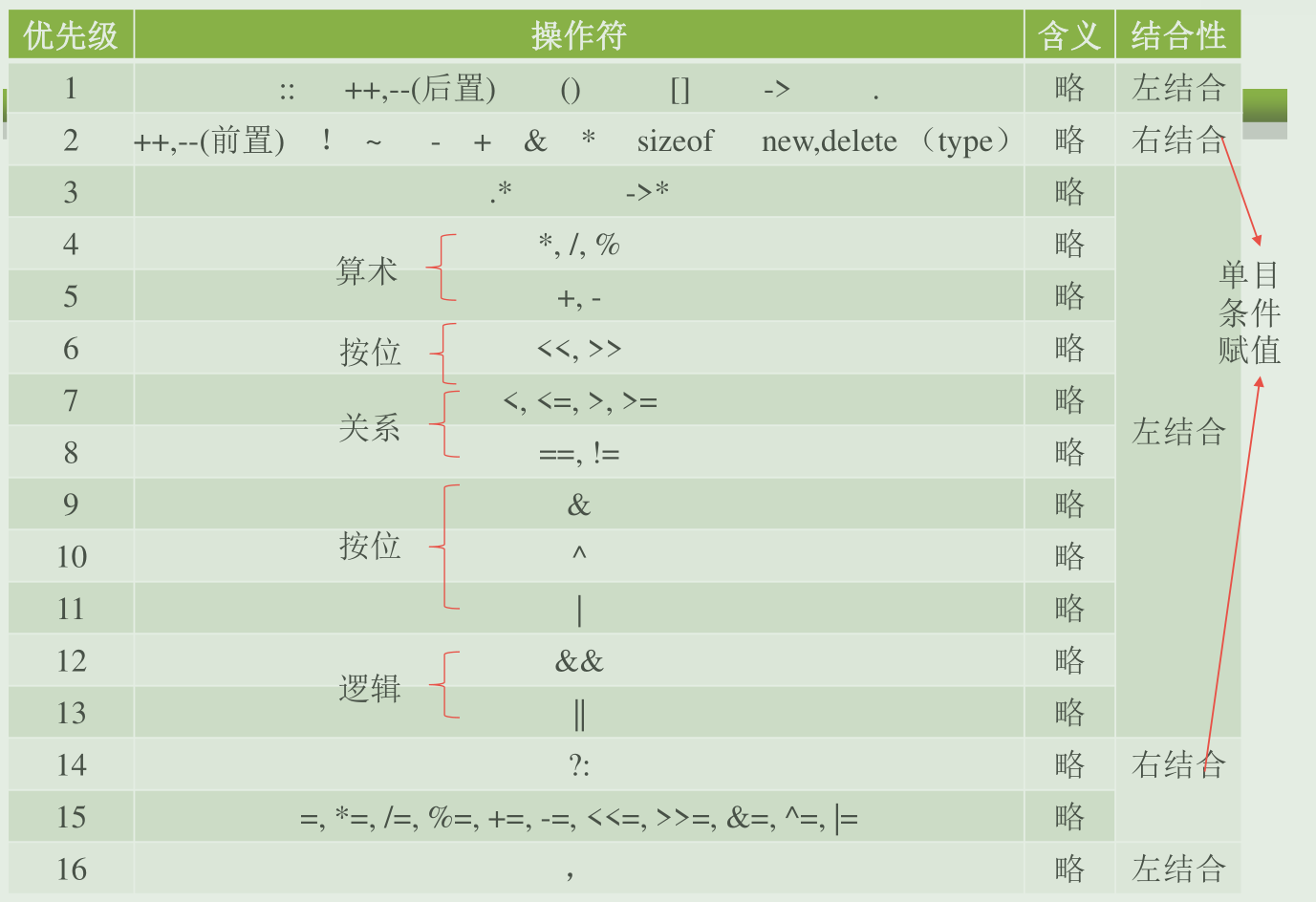
# (三)操作符
又称作:运算符 数据称为:操作数
操作符的优先级:
# 1. 算术操作符
- 加
+、减-、乘*、除/、取余% - 取负 取正
-+ - 自增、自减
++--
例题:可以使 x 的值增大 2: ++ ++x (++x)++
❌: x++ ++ ++x++
# 2. 关系与逻辑操作符
# (1)关系操作符
> < >= <= == !=
# (2)逻辑操作符
&& 逻辑与 || 逻辑或 ! 逻辑非
例:3&&5 的结果为:1
解析:3:11
5:101
11&&101 = 001 = 1
短路求值
# 3. 位操作符
# (1)逻辑位操作
~ 按位取反 二进制取反
& 按位与
例:若有变量定义 int a = 13, b = 6; 则表达式 a & b 的值为:4
13=1101
6=0110
1101 & 0110 = 0100 = 4
1101 ^ 0110 = 1011 = 11
| 按位或
^ 按位异或 相同为 0,不同为 1
(x^a)^a=x
# (2)移位操作
<<左移把第一个操作数按二进制位依次左移由第二个操作数所指定的位数。左移时,高位舍弃,低位补 0。
>>右移把第一个操作数按二进制位依次右移由第二个操作数所指定的位数。右移时,低位舍弃,高位按下面规则处理:
- 对于无符号数或有符号的非负数,高位补 0
- 对于有符号数的负数,高位与原来的最高位相同(适合于补码表示的整数)
移位操作常常用于实现特殊的乘法和除法运算。
例如,在某些情况下
- 把一个整型数按二进位左移一位相当于把该整型数乘以 2,
- 把一个整型数按二进位右移一位相当于把该整型数除以 2,
# 4. 赋值运算符
- cpp 允许连续使用赋值运算符
int a;
int b;
int c;
a=b=c=88;//88先被赋值给c,c的值被赋给b,b的值被赋给a# 5. 其他操作符
# (1)条件操作符
d1?d2:d3
如果 d1 的值为 true 或非零,则运算结果为 d2,否则为 d3
# (2)逗号操作符
d1,d2,d3,... 将若干个运算连接起来
从左至右依次进行各个运算,操作结果为最后一个运算的
结果。
例: x=a+b,y=c+d,z=x+y 等价于 z=a+b+c+d
# (3)sizeof 操作符
sizeof(类型名/变量名)计算各种数据类型的数据所占内存空间大小
CHAR_MAX
SHRT_MAX
INT_MAX
LONG_MAX
LLONG_MAX long long
typedef <已有类型> <别名>给已有数据类型取别名
# 6. 操作数的类型转换
# (1)隐式类型转换
char , short , int , unsigned int , long int , unsigned long int
(将 char , signed char , unsigned char , short int , unsigned short int )
float , double , long double
# (2)显式类型转换
<类型名>(<操作数>)
(<类型名>)<操作数>
# 三、控制语句
# (一)选择
# 1.if
# 2.switch
switch (<整型表达式>)
{
case<整型常量表达式>:
<语句>;
break;
case<整型常量表达式>:
<语句>;
break;
case<整型常量表达式>:
<语句>;
break;
...
default:<语句>;
}# (二)循环
# 1.while
# 2.do-while
do
{<语句>;
<语句>;
}while(<表达式>);注意:
while后的;
# 3.for
# (三)无条件转移
# 1.goto
- 不能用
goto从一个函数外部转入该函数内部,也不能用goto从一个函数内部转到该函数外部 - 不能掠过带有初始化的变量定义
# 2.break
- 立即跳出循环
# 3.continue
- 只能用在循环语句的循环体中
- 结束当前循环,进入下一次循环
# 4.return
# 四、函数
# 1. 函数定义
<返回值类型> <函数名> (<形式参数表>) <函数体>
例: int factorial(int n){ }
- return 语句:若返回值类型与 return 的类型不同,会存在隐式类型转换,把 return 的类型转成 <返回值类型>
- 函数的定义不可以嵌套
# 2. 函数调用
<函数名> (<实在参数表>)
例: factorial(5);
实参个数和类型与函数形参相同,若类型不同,会隐式转换,把实参类型转换成形参类型。
函数调用执行过程
计算实参的值
把实参分别传递给被调用函数的相应形参
为形参分配临时内存空间
执行函数体
为局部变量分配临时内存空间
当函数的语句部分执行结束后,释放进入函数时所申请的所有临时变量空间,这包括形式参数和局部变量两个部分。
函数体中执行
return语句返回函数调用点,调用点获得返回值(如果有返回值)并执行调用后的操作
函数参数传递
- 值传递(默认)
//例题 void swap(int x,int y){ int temp; temp = x; x = y; y = temp; } int main(){ int a = 2,b = 3; swap(a,b); cout << a << b << endl; return 0; } // 2 3- 地址或引用传递
# 3. 函数声明
- 调用的函数都要有定义,若定义在调用点之后或其他文件中,需要在调用前对被调用的函数进行声明。
<返回值类型> <函数名> (<形式参数表>)
或 extren <返回值类型> <函数名> (<形式参数表>)
- 在函数声明中,形式参数表可以只列出参数类型而不写形参名
例: int g(int,int);
- 在函数里面也可以声明
# 4. 局部变量与全局变量
# (1)局部变量
- 在复合语句中定义的变量,只能在定义他们的复合语句中使用
- 函数的形式参数与可以看成是局部变量
# (2)全局变量
在函数外部定义的变量
若全局变量定义在使用点之后或其他文件里,使用前需对其声明。
extern <变量类型> <变量名>变量定义也属于一种声明:定义性声明
- 变量定义要给变量分配空间,变量声明则不用
- 变量定义要给变量赋初值(初始化变量),变量声明则不可以。
- 变量定义只能有一个,变量声明可以有多个。
static全局变量:存储在静态存储区,在函数外部定义,只限在本文件中使用extern全局变量:存储在静态存储区,在其他文件中定义,在本文件中可以使用static局部变量:存储在静态存储区,在函数内部定义,只限在函数内部使用
# 5. 程序的多模块结构
一个程序模块包含两个部分:
- 接口 interface (.h 文件 头文件)在本模块中定义的、提供给其他模块使用的一些程序实体的定义(常量、类型等)和声明(函数、全局变量等)
- 实现 implementation (.cpp 文件 源文件)模块中程序实体的定义
在一个模块 A 中用到另一个模块 B 中定义的全局程序文件,要在 A 的源文件中用一条编译预处理命令(
#include)把 B 的头文件中的内容包含进来,达到声明的目的。文件包含命令:
#include <文件名>或#include "文件名"include 命令的含义是:在编译前,用文件名所指定的文件内容替换该命令
<文件名> 表示在系统指定的目录下寻找指定文件
"文件名" 表示先在 #include 命令的源文件所在的目录下查找,然后再在系统指定的目录下寻找指定文件
如果几个目录中都有 xx.h,
#include "xx.h"最多只会搜索到第一个就停止继续搜索
# 6. 标识符的作用域
# (1)局部作用域
在函数定义或复合语句中、从标识符的定义点开始到函数定义或复合语句结束之间的程序段。
具有局部作用域的标识符:局部常量名、局部变量名 / 对象名、函数的形参名
如果在一个标识符的局部作用域中包含内层复合语句,并且在该内层复合语句中定义了一个同名的不同实体,则外层定义的标识符的作用域应该是从其潜在作用域中扣除内层同名标识符的作用域之后所得到的作用域。
void f(){ int x;//外层x的定义 ... x ...//外层的x while ( ... x ...){//外层的x ...x...//外层的x double x;//内层的x ...x...//内层的x } ...x...//外层的x }
# (2)全局作用域
(具有全局作用域的标识符主要用于标识被程序各个模块共享的程序实体)
构成 c++ 程序的所有模块(源文件)
具有全局作用域的标识符:全局函数名、全局变量名 / 对象名、全局类名
若标识符的定义点在其它源文件中或在本源文件中使用点之后,则在使用前需要声明它们。
如果在某个局部作用域中定义了与某个全局标识符同名的标识符,则该全局标识符的作用域应扣掉与之同名的局部标识符的作用域。
int x;//外层x的定义 void f(){ ... x ...//外层的x while ( ... x ...){//外层的x ...x...//外层的x double x;//内层的x ...x...//内层的x } ...x...//外层的x }若在局部标识符的作用域中要使用与其同名的全局标识符,需要用全局域选择符(
::)对全局标识符进行修饰(受限)double x;//外 void f(){ ...x...//外 int x;//内 x//内 ::x//外 }
# (3)文件作用域
(具有文件作用域的标识符用于标识在一个模块内部共享的程序实体)
- 在全局标识符的定义中加上
static const定义的全局常量名- 具有文件作用域的标识符只能在定义他们的源文件(模块)中使用
# (4)函数作用域
- 语句标号 一个语句标号只能定义一次
# (5)函数原型作用域
- 用于函数声明的函数原型,其中的形式参数名的作用域从函数原型开始到函数原型结束。
void f(int x, double y);其中的 x 和 y 的作用域是从(开始到)结束
# (6)名空间作用域
- 在一个源文件中要用到两个分别在另外两个源文件中定义的不同全局程序实体(如:全局函数),而这两个全局程序实体的名字相同,C++ 提供了名空间 (namespace)设施来解决上述的名冲突问题。
- 在一个名空间中定义的全局标识符,其作用域为该名空间。
- 当在一个名空间外部需要使用该名空间中定义的全局标识符时,可用该名空间的名字来修饰或受限。
# 7. 变量的生存期(存储分配)
生存期:程序运行时一个变量占有内存空间的时间段
静态生存期
从程序开始执行时就进行内存空间分配,直到程序结束才收回它们的空间。全局变量具有静态生存期。静态数据区,系统将未显式初始化的变量初始化为 0
自动生存期
内存空间在程序执行到定义它们的复合语句 (包括函数体)时才分配,当定义它们的复合语句执行结束时,它们的空间将被收回。局部变量和函数的参数一般具有自动生存期。栈区 M
- 局部变量默认存储类为
auto使其具用自动生存期 register使局部变量具有自动生存期,由编译程序根据 CPU 寄存器的使用情况来决定是否存放在寄存器中static使局部变量具有静态生存期 只在函数第一次调用时进行初始化,以后调用中不再进行初始化,它的值为上一次函数调用结束时的值。
在全局标识符的定义中,
static用于把全局标识符的作用域改为文件作用域在局部变量的定义中,
static用于指出相应的局部变量具有静态生存期。- 局部变量默认存储类为
动态生存期
内存空间在程序中显式地用
new操作或malloc库函数分配、用delete操作或free库函数收回。动态变量具动态生存期。在 ** 堆区 (大小:G)** 中分配
# 8. 宏定义
一种编译预处理命令
#define <宏名> (<参数表>) <文字串>
例: #define max(a,b) ((a)>(b)?(a):(b))
# 9. 内联函数
- 在定义函数定义时,在函数返回类型之前加上一个
inline - 编译时,直接将被调函数体的代码直接插到调用处
- 可以提高程序的运行速度
- 有些函数即使加上了
inline关键词,编译程序也不会把它作为内联函数来对待(是否内联由编译器决定)
# 10. 带默认值的形式参数
有默认值的形参应处于形参表的右部。例如:
void f(int a, int b=1, int c=O);//OKvoid f(int a, int b=1, int c); //Error对参数默认值的指定只在函数声明处有意义。
在不同的源文件中,对同一个函数的声明可以对它的同一个参数指定不同的默认值;在同一个源文件中,对同一个函数的声明只能对它的每一个参数指定一次默认值。
# 11. 函数名重载
相同函数名,具有不同的参数列表(参数的类型或个数不同)
参数类型和个数相同,只有返回值类型不同不能对他们重载函数名
确定一个对重载函数的调用对应着哪一个重载函数定义的过程称为绑定(binding,又称定联、联编、捆绑)。
按参数类型匹配优先级:
- 精确匹配:细微的转换(数组名转化成第一个元素的指针、函数名转换成函数指针等)后相同
- 提升匹配
- 标准转换匹配
- 任何算术类型可以互相转换
- 枚举类型可以转换成任何算术类型
- 零可以转换成任何算术类型或指针类型
- 任何类型的指针可以转换成 void *
- 派生类指针可以转换成基类指针
- 每个标准转换都是平等的
- 自定义转换匹配
# 12.λ(lambda)表达式
匿名函数
[<环境变量使用说明>] <形式参数> <返回值类型> <函数体><环境变量使用说明>:
空:不能使用外层作用域中的自动变量
&:按引用方式使用外层作用域中的自动变量(可以改变这些变量的值)
=:按值方式使用外层作用域中的自动变量(不可以改变这些变量的值)
可以使用
&=统一指定外层作用域中的自动变量的使用方式,与可以在变量名前加$=(默认为=)单独指定
{ int k,m,n;
... [](int x) -> int {return x;} //不能使用k、m、n
...[&](int x) -> int {k++,m++,n++; return k+m+n+x;} //k、m、n可以被修改
...[=](int x) -> int {return k+m+n+x;} //k、m、n不可以被修改
...[&,n](int x) -> int {k++,m++; return x+k+m+n;} //n不能被修改
...[=,&n](int x) -> int {n++; return x+k+m+n;} //只有n能被修改
...[&k,m](int x) -> int {k++; return x+k+m;} //只能使用k、m,k可以被修改
...[=] {return k+m+n;} //没有参数,返回值类型为int(编译器自动确定)
}# 五、构造数据类型
# (一)枚举
设计者自己来定义值集的数据类型
# 1. 枚举类型的定义
enum <枚举类型名> {<枚举值表>}
例: enum Day {SUN,MON,TUE,WED,THU,FRI,SAT}
默认情况下,第一个枚举值为 0,以此加 1,也可以显式地给枚举值指定值。
例: enum Day {SUN=7,MON=1,TUE,WED,THU,FRI,SAT} TUE=2,WED=3......
- 枚举类型变量的定义:
<枚举类型名><变量表>;或enum <枚举类型名><变量表>; - 枚举类型和枚举类型变量同时定义:
enum Day {SUN,MON,TUE,WED,THU,FRI,SAT}d1,d2,d3;
# 2. 枚举类型的运算
赋值:
一个枚举类型的变量只能在相应枚举类型的值集中取值。
Day day; day = SUN;//OKday = 1;相同枚举类型之间可以进行赋值操作。
Day d1,d2; d2 = d1;可以把一个枚举值赋值给一个整型变量。
int a = d1;但不能把一个整型值赋值给枚举类型的变量.
d1 = a;d1 = (Day)a;//可以,但不安全
比较:
系统首先将枚举值转换为对应的整型值,然后进行比较。
算术运算:
运算时,将枚举值转换为对应的整型值。
不能对枚举类型的值直接进行输入,但可以进行输出。~~
cin >> d~~ 例:Day d; cout << d;//输出时,枚举类型的值将转换成int型
# (二)数组
# 1. 一维数组
# (1)定义:
- 直接定义变量
int a[10] - 定义数组类型,再定义变量
typedef int A[10];A a;(数组类型的元素个数是固定的,在程序执行中不能改变) - 不能通过赋值修改数组长度
# (2)变量的初始化
int a[10]={1,2,3,4,5,6,7,8,9,10};若初始化表中的值的个数少于数组元素个数,则不足部分的数组元素初始化为 0
int c[]={1,2,3};若对每个元素都进行了初始化,可以省略元素个数,元素个数由初始化的个数来定
若不使用
={}赋初值时(此时一定会定义长度),static和全局数组均默认其为 0 或‘0’,其他局部数组赋值随机
# 2. 一维字符数组
在字符串中最后一个字符的后面存储一个
'\0',作为字符串的结束标记若初始化表中的值的个数少于数组元素个数,则不足部分的数组元素初始化为 '\0'
初始化:
char s[10]={'h','e','l','l','o','\0'};(只有这种形式程序中必须显式的加上
'\0')char* buf1 = "abcd12345678"; char buf2[] = "abcd12345678"; cout << sizeof(buf1) << endl; //8 cout << sizeof(buf2) << endl; //13 (包含结束符\0) cout << strlen(buf1) << endl; //12 cout << strlen(buf2) << endl; //12 char a[]={'h','e','l','l','o'}; //长度为5 char a[]= "hello"; //长度为6
# 3. 二维数组
# (1)定义:
int a[10][5]typedef int A[10][5];A a;
# (2)初始化:
int a[2][3]={{1,2,3},{4,5,6}};或int a[2][3]={1,2,3,4,5,6};初始化的值可以少于数组元素的个数,元素默认初始化为 0
数组的行数可以省略,其行数由初始化的个数来决定(只能省略最高维)
int a[][3]={{1,2,3},{4,5,6},{7,8,9}};
由于不存在数组的长度这个属性,在将数组作为函数参数时,通常同时将长度作为参数传输
在 main 函数中可以使用
sizeof(a)获得数组长度
# (三)结构类型
# 1. 定义:
- 结构类型定义
struct <结构类型名> {<成员表>};例:
struct Student{
int no;
char name[20];
Sex sex;
};
enum Sex {MALE,FEMALE};变量定义
<结构类型名> <变量名表>或struct <结构类型名> <变量名表>例:Student a,b,c;也可以在定义结构类型的同时定义结构类型的变量,这时结构类型名可以省略,例:
struct{ int x; double y; }a,b;
struct默认访问权限是 public,class默认访问权限是 private
# 2. 初始化:
定义结构类型时不能对其成员初始化。因为类型不是程序运行时刻的实体,他们不占有内存空间,初始化没意义。可以在定义变量时初始化,例: Student a={2,Amy,FEMALE};
# 3. 访问结构的成员
<结构类型变量>.<成员名>
不同结构类型的成员的名字可以相同,它们可以与程序中非结构成员的名字相同;
结构类型的名字可以与同一作用域中的其他非结构类型标识符相同;
struct A{ ...; }; int A; ... struct A a;对于上述这种情况,使用结构类型 A 必须要在结构类型名前加上关键字
struct
# 4. 结构数据的赋值
- 对结构类型的数据可以整体赋值,但此操作必须要在相同的结构类型之间进行,不同类型结构之间不能相互赋值。
# (四)联合类型
# 1. 定义:
- 联合类型定义 例:
union A{ //A是一个联合类型
int i;
char c;
double d;
};
A a; //a是一个联合类型的变量
...a.i... //可以把a作为int型来用联合类型的所有成员占有同一块内存空间,该内存空间的大小为其最大成员所需要的内存空间的大小。
- 可以进行整体赋值,可传给函数,可作为函数返回值
# (五)指针类型
# 1. 指针类型的定义
指针是内存地址的抽象表示,一个指针代表了一个内存地址
获取变量的地址:
&<变量名>每一个地址都属于某一种指针类型
<类型> *<指针变量>
例: int *p,*q; //p q均为指针变量
`int *p,q; //p为指针变量,q为int型变量`
`int* p,q; //p为指针变量,q为int型变量`
typedef <类型>* <指向数据类型数据的指针类型>; <指向数据类型数据的指针类型> <指针类型的变量名>;例:`typedef int* Pointer;` `Pointer p,q;` - `void *p` 表明该指针变量可以指向任意类型的数据 - 符号常量`NULL` 空指针 > 指针变量拥有自己的内存空间,**在该空间中存储的是另一个数据的内存地址** > > 例:`int x=1; int *p=&x;` #### 2.指针类型的基本操作 ##### (1)赋值 ```c++ int x,*p,*p1; double y,*q; ...... //相同类型指针变量可以互相赋值 p = &x; q = &y; p = &y; //Error 类型不同不能赋值 p1 = p; p = 0; //使得p不指向任何变量 p = 120; //Error 120为int型
任意类型的都可以赋给
void*类型的指针变量
# (2)间接访问操作
*<指针变量> 访问指针变量所指向的变量
int x;
int *p = &x;
//赋值:
x = 1; //或
*p = 1; //此时x=1使用指针变量前,必须先给它赋一个指向合法具体对象的地址值
Error:
int *px; *px = x;Error:
char *s; cin>>s;
# (3)指针的运算
# ①一个指针加上或减去一个整型值
通常用此访问数组元素
一个指针可以与一个整型值进行加或减运算,运算结果为与该指针同类型的指针
int a[10];
int *p = &a[0]; //p指向数组a的第0个元素
p = p + 3; //p指向数组a的第3个元素
p++; //p指向数组a的第4个元素int *p;
double *q;
p++; //p的值加sizeof(int)
q -=4; //q的值减4*sizeof(double)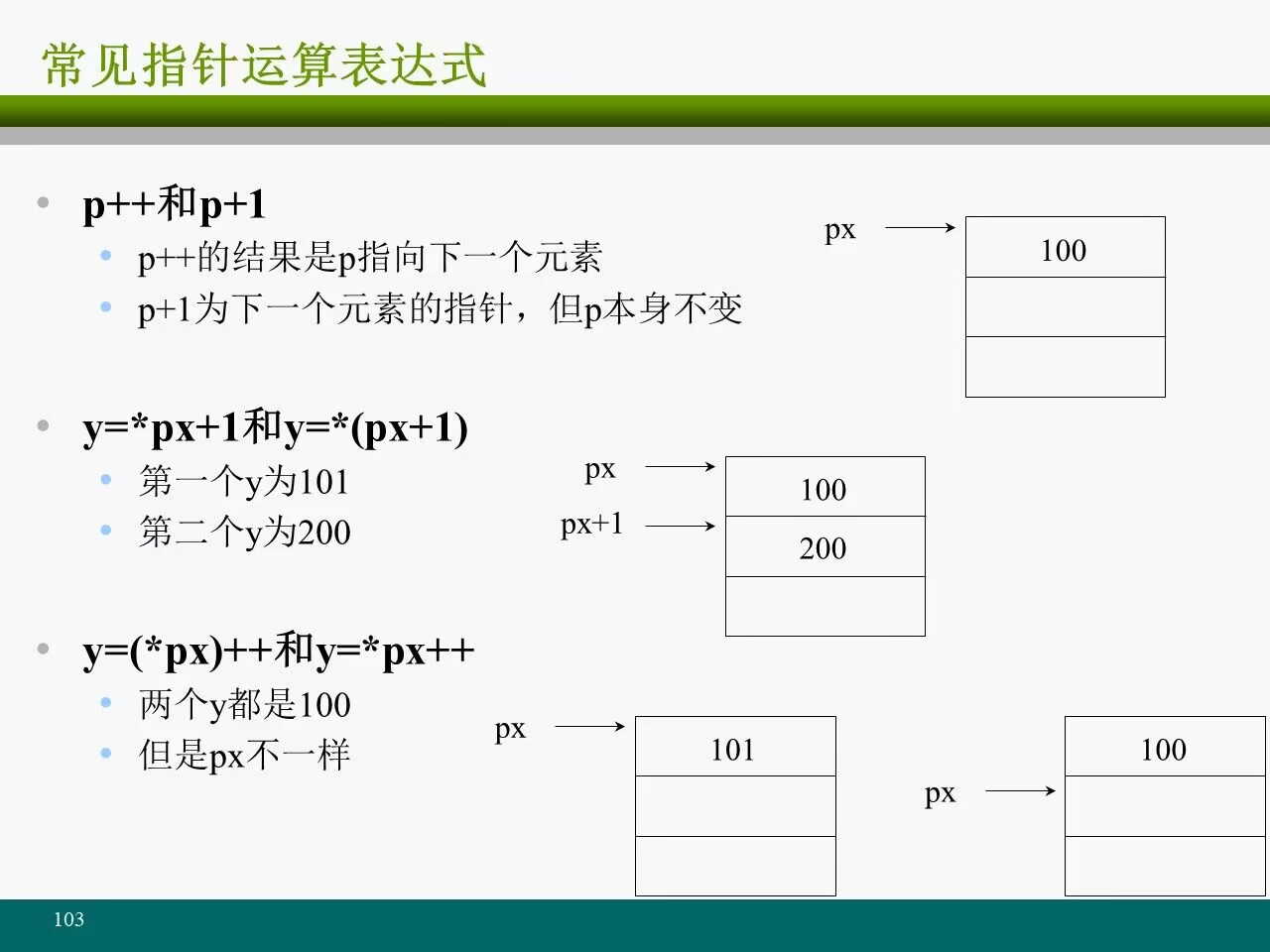
y = *px++; 相当于 y = *px (px++) (取当前元素,指向下一个)
# ②两个同类型的指针相减
两个同类型的指针相减,结果为两个指针之间相差元素的个数
两个指针不能相加
int a[10];
int *p = &a[0];
int *q = &a[3];
cout << q-p << endl; //输出3# ③两个同类型的指针比较
即:比较他们所对应的内存地址的大小
int a[10],sum = 0,*p = &a[0],*q = &a[3];
while(p<=q){
sum += *p;
p++;
}# (4)指针的输出
int x=1;
int *p=&x;
cout << p; //输出p的值(x的地址)
cout << *p; //输出p指向的值(x的值)- 当输出字符指针
*char时,输出的不是指针值,而是该指针所指向的字符串(特例)
char str[] = "ABCD";
char *p=&str[0];
cout << p; //输出p指向的字符串:ABCD
cout << *p; //输出p指向的字符:A
cout << (void *)p; //输出p的值,即字符串"ABCD"的内存首地址# 3. 指针作为参数类型
# (1)提高传参效率
# (2)通过参数返回函数的计算结果
void swap(int *px, int *py){
int t = *px;
*px = *py;
*py = t;
}
int main(){
int a=0.b=1;
swap(&a,&b);
cout << a << " " << b; // 1 0
}# (3)指向常量的指针
- 指向常量的指针(常量指针)
const <类型> *<指针变量>
const int *p; //p为指向常量的指针变量
const int x = 0; // 常量必须初始化
p = &x;
*p = 1; //Error 不能通过常量指针改变它所指向的常量的值
int *q;
q = &x; //Error 指向变量的指针变量不能指向一个常量int a,b;
const int *p=&a //常量指针 可以指向变量(但不能改变其值)
//那么分为一下两种操作
*p=9; //操作错误
p=&b; //操作成功- 指针类型的常量(指针常量)是一个常量,但是是指针修饰的
int x,y;
int *const p = &x; //定义了一个指针类型的常量p,p指向一个变量
*p = 1; //*p是一个常量
p = *y; //Error p是一个常量,其值不能被修改int a,b;
int * const p=&a //指针常量
//那么分为一下两种操作
*p=9;//操作成功
p=&b;//操作错误
const <类型> *常量指针:不可以改变值,可以改变指向* const指针常量:不可以改变指向,可以改变值
- 指向常量的指针常量
const int x = 0,y = 1;
const int * const p = &x; //p是一个指向常量的指针常量例:C(A B 相同)
以下哪个仅表示指针指向不能变
A.const char*
B.char const*
C.char* const
D.const char* const# (4)作为返回值类型
int *max(const int x[], int num){
int max_index=O;
for (int i=1; i<num; i++){
if(x[i]> x[max_index]){
max_index = i;
}
}
return (int*)&x[max_index];
}
int main(){
int a[100];
...
cout << *max(a,100)<< endl;
return 0;
}
- 不能把局部量的地址作为指针返回给调用者
int *f(){
int i=O;
return &i;
} //f调用完i的变量空间就归还了
int*g(){
int j=1; //j与i分配的是同一块空间
return &j;
}
int main(){
int x ;
int *p=f();
int *q=g();
x=*p+*q;
cout <<x <<endl; //输出2 (p和q用的同一空间,地址相同,该内存空间最后的值是1)
return 0;
}
# 4. 指针与动态变量
- 数组元素个数不能是变量,必须在编译时就能确定它的值是多少
int n; cin >> n; int a[n];
# (1)动态变量的创建
动态变量是指在程序运行中,由程序根据需要所创建的变量。
# ① new <类型名>
int *p, *p0;
p = new int;//创建了一个int型动态变量,p指向该变量
*p = 1; //只能通过改变指针变量来访问该动态的整型变量
p0 = new int(10); //创建一个int型数,并且用()括号中的数据进行初始化new 操作类型应保持一致
# ② new <类型名> [][]
除第一维的大小外,其他维的大小必须是常量或常量表达式
int *p; //p为指向一个int型数据的指针
int n;
p = new int[n];
//用 p[i]访问第i个元素int (*q)[20]; //q为一个指向由20个int型元素所构成的一维数组的指针
//等价于typedef int A[20]; A *q;
int n;
...
q= new int[n][20]; //创建一个n行、20列的二维动态数组,返回第一行的地址。 等价于: q=new A[n];
...q[i][j]... //访问q指向的二维数组的第i行第j列的元素如何创建一个 m 行、n 列的动态数组?
用一维数组实现:
int *p=new int[m*n];第 i 行、第 j 列元素:
*(p+i*n+j)
# ③ void *malloc(unsigned int size)
#include <cstdlib>
int *p1,*p2,*r;
typedef int A[20];
A *q;
int m,n;
...
p1 = (int *)malloc(sizeof(int)); //创建一个int型动态变量
p2 = (int *)malloc(sizeof(int)*n); //创建一个由n个int型元素构成的一维动态数组变量
q = (A *)malloc(sizeof(int)*n*20);//创建一个n行20列的二维动态数组变量
r = (int *)malloc(sizeof(int)*m*n); //创建一个隐含的m行n列的二维动态数组变量newmalloc区别:new自动计算所需分配的空间大小,而malloc需要显式指出new自动返回相应类型的指针,而malloc要做显式类型转换
# (2)动态变量的访问
动态变量没有名字,对动态变量的访问需要通过指向动态变量的指针变量来进行(间接访问)。
int *p,*q;
p =new int;
...*p... //访问上面创建的int型动态变量q=new int[n];
...*(q+3)... //或...q[3]...访问上面创建的动态数组中的第4个元素# (3)动态变量的撤销
在 C++ 中,动态变量需要由程序显式地撤消(使之消亡)
例如:
delete p;//撤消p指向的int型动态变量或free(p);再例如:
delete []q;//撤消q指向的动态数组或free(q);一般来说,用 new 创建的动态变量需要用 delete 来撤销;用 malloc 创建的动态变量则需要用 free 撤销。
# ① delete <指针变量>
int *p = new int;
delete p;# ② delete []<指针变量>
int *p = new int[20];
delete []p;# ③ void free(void *p)
p1 = (int *)malloc(sizeof(int));
q = (A *)malloc(sizeof(int)*n*20);
free(p);
free(q);用 delete 和 free 只能撤消动态变量!
int x,*p; p = &x; delete p;用 delete 和 free 撤消动态数组时,其中的指针变量必须指向数组的第一个元素
int *p = new int[n]; p++; delete []p;悬浮指针
用 delete 或 free 撤消动态变量后,C++ 编译程序一般不会把指向它的指针变量的值赋为 0,这时该指针指向一个无效空间。
int *p; p = new int; delete p;//撤销了p所指向的动态变量 *p= 1;//逻辑错误,P指向的内存空间已经分配给其他动态变量了内存泄漏
没有撤消动态变量,而把指向它的指针变量指向了别处或指向它的指针变量的生存期结束了,这时,这个动态变量存在但不可访问(这个动态变量已成为一个 “孤儿”),从而浪费空间。
int x,*p; p = new int[10];//动态数组 p=&x; //之后,上面的动态数组就访问不到了!
# 5. 指针与数组
指针访问数组元素能提高效率
# (1)一维数组的首地址
int a[10]; //等价于: typedef int A[10]; A a;# ①通过数组首元素来获得
int *p;
p = &a[0];
或
p = a; //把一维数组a隐式类型转换成第一个元素的地址: &a[0]
p++;把一维数组传给一个函数时,编译器也会对数组变量进行类型转换 例:
int a[10]; f(a);相当于f(&a[0]);字符串常量也可隐式转换成他的第一个字符在内存中的首地址。
# ②通过整个数组获得
A *q;//或int(*q)[10];
q = &a; //整个数组的地址,它与&a[0]值相同,但类型不同
q++;//加:10×sizeof(int)
//q为1x10的二维数组,q[0][i]或(*q)[i]用于按行来访问二维数组当创建一个动态的一维数组时,得到的是第一个元素的地址。例如:
int n; int *p; p = new int[n];//创建一个由n个int型元素构成的一维动态数组,返回第一个元素的地址,其类型为: int *
# (2)多维数组的首地址
int b[5][10];//等价于: typedef int A[10]; A b[5];int b[2][3]={1,2,3,4,5,6}
# ①通过第一行第一列元素来获得
int *p;
p= &b[0][0];//或p= b[0];(自动转换成&b[0][0])第一行第一列元素的地址
p++;//加:sizeof(int)- 访问元素
p[i]*(p+i)
# ②通过第一行的一维数组来获得
A *q; //或int (*q)[10];
q=&b[0];//或q=b; (自动转换成&b[0]) 第一行的地址
q++; //加:10×sizeof(int) q指向下一行- 访问元素
q[i][j]*(*(q+i)+j)
q++ (此时指向第 1 行) **q 4(第 1 行第 0 个元素) *(*q+1) 5(第 1 行第 1 个元素) (*q)[1] 5
# ③通过整个数组来获得
B *r; //或int (*r)[5][10];
r =&b;//整个二维数组的地址
r++; //加:5×10×sizeof(int)
//在三维数组中使用访问元素
r[0][i][j]*(r)[i][j]例题:
设int a[3][4]={{1,3,5,7},{2,4,6,8}};则*(*a+1)的值为 3 (第0行第1个元素)对于一个动态的 n 维数组,实际上是按一维动态数组来创建的,返回的首地址类型是去掉第一维后的数组指针类型。例如,下面创建一个动态的二维数组:
typedef int A[10];//A表示一个由10个int型元素所构成的一维数组类型 int m; A *q;//或: int(*q)[10]; q= new int[m][10];//创建一个由m行10列的二维数组,返回第一行的地址(类型为:A*)。 或 q=new A[m];
# (3)函数 main 的参数
可以给函数 main 定义参数,其定义格式为:
int main(int argc, char *argv[]);argc表示传给函数 main 的参数的个数,argv表示各个参数,它是一个一维数组,其每个元素为一个指向字符串的指针。以
“copy file1 file2”执行程序 copy 时,copy 的函数 main 将得到参数:
argc:3
argv[0]: "copy"argv[1]: "file1"
argv[2]: "file2"
# 6. 函数指针
C++ 中可以定义一个指针变量,使其指向一个函数。
函数指针定义格式:
<返回类型> (*<指针类型>)(<形式参数表>)
double (*fp)(int);//fp是一个指向函数的指针变量
或者
typedef double (*FP)(int);
FP fp; 对于一个函数,可以用取地址操作符
&来获得它的内存地址,或直接用函数名来表示。double f(int x){ ...} fp= &f;//或者,fp =f;通过函数指针调用函数可采用下面的形式
(*fp)(10); //或者,fp(10);
//函数指针,可以指向有相同参数列表和返回值的不同名函数
int max(int x,int y){
return x>y?x:y;
}
int min(int x,int y){
return x>y?y:x;
}
void main(void){
int (*p)(int,int);
p = max;
cout << p(3,5) << endl;
p = min;
cout << p(3,5) << endl;
}
A:指向整型量的指针
B:指向字符型的指针
C:由指向字符的指针构成的数组,即指针数组
D:指向字符数组的指针,即数组指针
F:返回值为指向整型量的指针的函数,即指针函数
G:指向返回值为整型量的函数的指针,即函数指针
# 7. 多级指针
(可能不考 待补充)
# (六)引用类型(变量的别名)
# 1. 定义
定义格式:
<类型> &<引用变量>=<变量>int x=O; int &y=x;//y为引用类型的变量,可以看成是x的别名 cout <<x<<','<<y << endl;//结果为:0,0 y = 1; cout <<x <<','<<y <<endl;//结果为:1,1引用类型用于给一个变量取一个别名。
在语法上,
对引用类型变量的访问与非引用类型相同。在语义上,
对引用类型变量的访问实际访问的是另一个变量(被引用的变量)。
效果与通过指针间接访问另一个变量相同。对引用类型需要注意下面几点:
- 定义引用类型变量时,应在变量名加上符号 “&”,以区别于普通变量。
- 定义引用变量时必须要有初始化,并且引用变量和被引用变量应具有相同的类型。
- 引用类型的变量定义之后,它不能再引用其它变量。
引用本质:指针常量
指针指向不可变,指针指向的值可变
# 2. 引用类型作为函数的参数类型
通过形参改变实参的值
#include <iostream> using namespace std; void swap(int &x, int &y){//交换两个int型变量的值 int t; t = x; x = y; y = t; } int main(){ int a=0,b=1; cout <<a<<','<<b<< endl; //结果为:0,1 swap(a,b); cout <<a<<','<<b<<endl; //结果为:1,0 return 0; }指针的引用
#include <iostream>
using namespace std;
void swap(int *&x, int *&y){//交换两个int型指针变量的值
int *t;
t = x;
x = y;
y = t;
}
int main(){
int a=0,b=1;
int *p=&a,*q=&b;
cout <<*p<<','<<*q<< endl; //p指向a,q指向b 结果为:0,1
swap(p,q);
cout <<*p<<','<<*q<<endl; //p指向b,q指向a 结果为:1,0
return 0;
}- 引用做函数返回值类型
//返回数组中最大元素的引用(注意:不能返回局部变量的引用)
int &max(int x[], int num){
int i, j;
j = 0;
for (i=1;i<num;i++){
if(x[i]>x[j]){
j = i;
return x[j];
}
}
}
//引用具有左值,可以通过返回的引用修改值
int a[10];
cout<<max(a,10)<<endl;
max(a,10)+=1; //把数组最大元素的值+1通过把形参定义成对常量的引用,可以防止在函数中通过引用类型的形参改变实参的值。
引用类型与指针类型的区别
引用类型和指针类型都可以实现通过一个变量访问另一个变量,但在语法上,
引用是采用直接访问形式
指针则需要采用间接访问形式
在作为函数参数类型时,
引用类型参数的实参是一个变量的名字
指针类型参数的实参是一个变量的地址
在定义时初始化以后,
- 引用类型变量不能再引用其它变量
- 指针类型变量可以指向其它的变量
引用类型一般作为指针类型来实现(有时又把引用类型称作隐蔽的指针,hidden pointer)
能够用引用实现的指针功能,尽量用引用!
# 六、对象与类
# (一)面向对象程序设计
# 1. 基础
# (1)数据抽象
- 数据的使用者只需要知道对数据所能实施的操作以及这些操作之间的关系,而不必知道数据的具体表示。
# (2)数据封装
指把数据及其操作作为一个整体来进行描述。
数据的具体表示对使用者是不可见的,对数据的访问只能通过封装体所提供的对外接口 (操作)来完成。
# (3)栈
栈是一种由若干个具有线性次序关系的元素所构成的复合数据。对栈只能实施两种操作:
进栈(push): 往栈中增加一个元素
退栈(pop): 从栈中删除一个元素
上述两个操作必须在栈的同一端(称为栈顶,top)进行。后进先出
(Last In First Out,简称 LIFO) 是栈的一个重要性质
# 2. 对象和类
- 对象是由数据及能对其实施的操作所构成的封装体,它属于值的范畴。
- 类描述了对象的特征(包含哪些数据和操作),它属于类型的范畴 (对象的类型)。
- 数据:数据成员、成员变量、实例变量、对象的局部变量等
- 操作:成员函数、方法、消息处理过程等
# 3. 继承 (Inheritance)
- 在定义一个新类(派生类、子类)时,可以利用已有类(基类、父类)的一些特征描述。
- 单继承与多继承
- 作用:分类、代码复用等
# 4. 多态与绑定
多态性 (Polymorphism) 动态绑定 (Dynamic Binding)・
# (1)多态
- 某一论域中的一个元素存在多种解释。通常体现为:
- 一名多用:
- 函数名重载
- 操作符重载
- 类属性:
- 类属函数:一个函数能对多种类型的数据进行操作。
- 类属类型:一个类型可以描述多种类型的数据。
- 一名多用:
- 面向对象程序特有的多态(动态多态):
- 对象类型的多态:子类对象既属于子类,也属于父类
- 对象标识的多态:父类的引用或指针可以引用或指向子类对象
- 消息的多态:一个消息集有多种解释(父类与子类有不同解释)
# (2)绑定
- 确定对多态元素的某个使用是多态元素的那一种形式。
- 静态绑定(Static Binding,也称前期绑定,EarlyBinding): 在编译时刻确定。
- 动态绑定(Dynamic Binding,也称后期绑定或延迟绑定 Late Binding): 在运行时刻确定。
- 多态带来的好处:
- 易于实现程序高层 (上层)代码的复用。
- 使得程序扩充变得容易(只要增加底层的具体实现)。
- 增强语言的可扩充性(操作符重载等)。
# (二)类
对象构成了面向对象程序的基本计算单位,而对象的特征则由相应的类来描述。类也可看成是对象的集合。
# 1. 数据成员
数据成员指类的对象所包含的数据,它们可以是常量和变量。数据成员的说明格式与非成员数据的声明格式相同
class Datell{//类定义 private://访问控制说明 int year,month,day;//数据成员说明 }; 例如:class A{ int x=0;//Error const double y=0.0;//Error };说明数据成员时不允许进行初始化。
# 2. 成员函数
成员函数描述了对类定义中的数据成员所能实施的操作。
成员函数的实现也可以放在类定义外
class A{ void f();//声明 }; void A::f() {...} //定义,非内联函数,需要用类名受限,区别于全局函数。 或 inline void A:f() {...} //显式说明该成员函数也是一个内联函数类成员函数名是可以重载的(析构函数除外),遵循一般函数名的重载规则
成员函数可以对其形参设置默认值
# 3. 成员的访问控制
class A
{ public://访问不受限制。
int x;
void f();
private: //只能在本类和友元的代码中访问。
int y;
void g();
protected: //只能在本类、派生类和友元的代码中访问。
int z;
void h();
}- 在 C++ 的类定义中,默认访问控制是 private(结构和联合成员的默认访问控制为 public)
可以有多个 public、private 和 protected 访问控制说明
# (三)对象
# 1. 对象的创建
# (1)直接方式
Date today,yesterday
- 全局对象:在函数外定义的对象
- 局部对象:在函数内定义的对象
# (2)间接方式(动态对象)
在程序运行时刻,通过
new操作来创建对象,用delete操作来撤消 (使之消亡)。new创建对象自动调用构造函数delete释放对象自动调用析构函数而
malloc与free则否通过指针来标识和访问。
单个动态对象的创建与撤消
A *p; p =new A;//创建一个A类的动态对象 ...*p...//通过p访问动态对象 delete p;//撤消p所指向的动态对象。动态对象数组的创建与撤消
A *q; q= new A[100]; //创建一个动态对象数组。 ...q[i]...//或者,*(q+i),通过q访问动态对象数组 delete []q; //撤消q所指向的动态对象数组。
# 2. 对象的操作
- 非动态对象
<对象>.<类成员> - 动态对象
<对象指针>-><类成员>或(*<对象指针>).<类成员>
class A{
int x;
public:
void f();
};
int main(){
A a;//创建A类的一个局部对象a。
a.f();//调用A类的成员函数f对对象a进行操作。
A *p=new A;//创建A类的一个动态对象,p指向之。
p->f();//调用A类的成员函数f对p所指向的对象进行操作。
delete p;
return 0;
}在类的外部,通过对象来访问类的成员时要受到类成员访问控制的限制
可以对同类对象进行赋值
Date yesterday,today,some_day; some_day = yesterday;//把对象yesterday的数据成员分别赋值给对象some_day的相应数据成员。取对象地址
Date *p_date; p_date = &today;//把对象today的地址赋值给对象指针p_date。把对象作为实参传给函数以及作为函数的返回值等操作。
Date f(Date d){ Date x; return x; some_day2 = f(yesterday);//调用函数f,把对象yesterday作为实参。返回值对象赋给对象some_day2。 }
# 3. this 指针
类定义中说明的数据成员(静态数据成员除外)对该类的每个对象都有一个拷贝。
实际上,每一个成员函数都有一个隐藏的形参
this,其类型为:<类名>*const this;成员函数所属对象的指针,明确地表示了成员函数当前操作数据所属对象
在成员函数中对类成员的访问是通过 this 来进行的。
一般情况下,类的成员函数中不必显式使用 this 指针来访问对象的成员(编译程序会自动加上)。
如果成员函数中要把 this 所指向的对象作为整体来操作(如:取对象的地址),则需要显式地使用 this 指针。
void func(A *p); class A{ int x; public: void f(){func(this);} //!!! void g(int i){x = i; f();} }; ... A a,b; a.f(); //要求在f中调用func(&a) b.f(); //要求在f中调用func(&b)
# (四)对象的初始化和消亡前处理
# 1. 构造函数 (Constructors)
# (1)定义
构造函数是类的特殊成员函数,它的名字与类名相同、无返回值类型。创建对象时,构造函数会自动被调用。
class A{ int x,y; public: A(){x =0; y = 0;}//构造函数 ... }; A a; //创建对象a:为a分配内存空间,然后调用a的构造函数A()构造函数可以重载,其中,不带参数的(或所有参数都有默认值的)构造函数被称为默认构造函数。(可以不用实参进行调用的构造函数)
构造函数一般为
public可以设置为private
# (2)调用
- 对象创建后不能再调用构造函数,构造函数的调用是对象创建过程的一部分。
class A{
...
public:
A();
A(int i);
A(char *p);
};
...
A a1; //调用默认构造函数 也可写成: A a1=A(); 但不能写成: A a1();
A a2(1); //调用A(int i) 也可写成:A a2=A(1); (显示)或 A a2=1;(隐式)
A a3("abcd"); //调A(char *) 也可写成:A a3=A("abcd"); 或A a3="abcd";
A a[4];//调用对象a[0]、a[1]、a[2]、a[3]的默认构造函数。
A b[5]={A(),A(1),A("abcd"),2,"xyz"}; //调用b[0]的A()、b[1]的A(int)、b[2]的A(char *)、b[3]的A(int)和b[4]的A(char *)
A *p1=new A;//调用默认构造函数。
A *p2=new A(2);//调用A(int i)。
A *p3=new A("xyz");//调用A(char *)。
A *p4=new A[20];//创建动态对象数组时只能调用各对象的默认构造函数# (3)成员初始化表
对于常量数据成员和引用数据成员(某些静态成员除外),不能在说明它们时初始化,也不能采用赋值操作对它们初始化(说明数据成员时不允许初始化)
对于常量数据成员和引用数据成员,可以在定义构造函数时,在函数头和函数体之间加入一个成员初始化表来对它们进行初始化。例如:
class A{ int x; const int y; int &z; public: A():x(0),z(x),y(1) //成员初始化表(按照 x(0) y(1) z(x)顺序初始化) {} };成员初始化表中成员初始化的书写次序并不决定它们的初始化次序,数据成员的初始化次序由它们在类定义中的说明次序来决定。
先初始化再执行构造函数体
例题:假定 MyClass 为一个类,执行
MyClass a[3],*p[2];语句时会自动调用该类构造函数 (3) 次
# 2. 析构函数 (Destructors)
~<类名> 没有返回类型、不带参数、不能被重载
- 一个对象消亡时,系统在收回它的内存空间之前,将会自动调用析构函数。
- 可以在析构函数中完成对象被删除前的一些清理工作(如归还对象额外申请的资源等)。
- 析构函数的调用顺序与构造函数的调用顺序完全相反
class String{
int len;
char *str;
public:
String(char* s){
len = strlen(s);
str = new char[len+1];//申请资源
strcpy(str, s); //复制字符串
}
~String(){
delete[] str;//归还资源
str=NULL;//一般情况下不需要这条语句,有时需要
}
}
void f(){
String s1("abcd");//调用s1的构造函数
......
}//调用s1的析构函数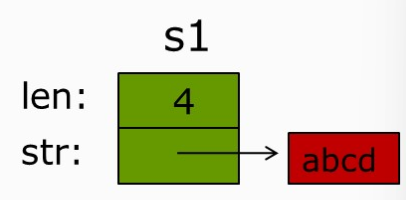
注意:系统为对象 s1 分配的内存空间只包含 len 和 str(指针)本身所需的空间,str 所指向的空间不由系统分配,而是由对象作为资源自己处理!
- 析构函数可以显式调用
- 把 string 类的对象 s 变成空字符串的对象,显式调
s1.~String();(只归还对象的资源,对象并未消亡!) - 注意:一般不需要自定义析构函数
- 需要时系统隐式提供,如:需要调用成员对象类和基类的析构函数
- 归还资源时需自定义
# 总结对比
# 构造函数的特殊性质
- 构造函数的名字必须与类名相同
- 构造函数不指定返回类型,它隐含有返回值,由系统内部使用
- 构造函数可以有一个或多个参数,因此构造函数可以重载
- 在创建对象时,系统会自动调用构造函数
# 析构函数的特殊性质
析构函数名是在类名前加
~符号析构函数不指定返回类型,它不能有返回值
析构函数没有参数,因此析构函数不能重载,一个类中只能定义一个析构函数
在撤销对象时,系统会自动调用析构函数
析构与构造顺序相反
如果一个类没有定义构造和析构函数,则编译器将生成默认构造函数(不必为其提供参数的构造函数)和默认析构函数
例题 1
//date.h
class Date{
int year, month, day;
public:
Date(int y, int m, int d); //构造函数1
Date(int y=2000): year(y){ //构造函数2
month = 4;
day=8;
cout<<"Constructor of Date with 1 parameter."<<endl;
}
~Date(){
cout<<"Destructor of Date: "<<year<<"."<<month<<"."<<day<<endl;
}
int IsLeapYear();
void Print(){cout<<year<<"."<<month<<"."<<day<<endl;}
}
//date.cpp
Date::Date(int y, int m, int d):year(y),month(m), day(d){
cout<<"Constructor of Date with 3 paramenters."<<endl;
}
int Date::IsLeapYear(){
return (year%4==0 && year%100= 0) || (year%400)==0;
}
//example.cpp
#include“date.h”
int main()
{
Date date1(2022,4,8), date2; //分别调用构造函数1,2
cout<<"date1:";
date1.Print();
cout<<"date2:";
date2.Print();
if(date2.IsLeapYear()){
cout<<"date2 is a leapyear."<<endl;
else
cout<<"date2 is not a leapyear. "<<endl;
return 0;
}//分别调用析构函数
/*
Constructor of Date with 3 paramenters.
Constructor of Date with 1 paramenters.
date1: 2022.4.8
date2: 2000.4.8
date2 is leapyear.
Destructor of Date: 2000.4.8
Destructor of Date: 2022.4.8
*/对象数组
- 数组元素为对象的数组,即数组中每个元素都是同一个类的对象
- 对象数组的格式:
<类名><数组名>[<大小>]…..DATE dates[5];
使用对象数组成员:<数组名>[<下标>].<成员名>dates[0].year
class DATE
{
int year, month, day;
public:
DATE():month(0), day(0), year(0){
cout<<"Default constructor called."<<endl;
}
DATE(int m, int d, int y):month(m), day(d), year(y){
cout<<"Constructor called."<<day<<endl;
}
~DATE(){
cout<<"Destructor called."<<day<<endl;
}
void Print() const{
cout<<"Month="<<month<<", Day="<<day<<", Year="<<year<<endl;
}
};
int main(){
DATE dates[5]={DATE(10,1,2002),DATE(10,2,2002),DATE(10,3,2002)};
dates[3] = DATE(10,4,2002);
dates[4] = DATE(10,5,2002);
for(int i=0;i<5;i++) dates[i].Print();
return 0;
}
/*
Constructor called.1
Constructor called.2
Constructor called.3
Default constructor called.
Default constructor called.
Constructor called.4
Destructor called.4 //!
Constructor called.5
Destructor called.5 //!
Month = 10, Day = 1, Year = 2002
Month = 10, Day = 2, Year = 2002
Month = 10, Day = 3, Year = 2002
Month = 10, Day = 4, Year = 2002
Month = 10, Day = 5, Year = 2002
Destructor called.5
Destructor called.4
Destructor called.3
Destructor called.2
Destructor called.1
*/自由存储对象
- 在程序运行过程中根据需要可以随时建立或者删除的对象称为自由存储对象(建立及删除可使用 new 和 delete)
Class test{
int X, Y;
public:
Test();
Test(int i, int j);
~Test(){cout<<“Destructor called: ”<< X <<“,”<< Y << endl;}
void Set(int i, int j);
void Print(){cout<< X <<“, ”<< Y <<endl;}
};
Test::Test(): X(0), Y(0){
cout<<“Default constructor called. ”<<endl;
};
Test::Test(int i, int j): X(i), Y(j){
cout<<“Constructor called: ”<< X <<‘, ’<< Y <<endl;
};
void Test::Set(int i, int j){X=i, Y=j};
int main(){
Test *ptr1, *ptr2, *ptr3;
ptr1 = new Test(1, 2);
ptr2 = new Test(3, 4);
ptr3 = new Test[2];
ptr3[0].Set(5, 6);
ptr3[1].Set(7, 8);
ptr1->Print();
ptr2->Print();
ptr3[0].Print();
ptr3[1].Print();
delete ptr1;
delete ptr2;
delete [] ptr3;
return 0;
}
/*
Constructor called: 1, 2
Constructor called: 3, 4
Default constructor called.
Default constructor called.
1, 2
3, 4
5, 6
7, 8
Destructor called: 1, 2
Destructor called. 3, 4
Destructor called: 7, 8
Destructor called. 5, 6
*/# 3. 成员对象的初始化
成员对象:
对于类的数据成员,其类型可以是另一个类。也就是说,一个对象可以包含另一个对象(称为成员对象)
class A{ ... }; class B{ ... A a; //成员对象 ... }; B b; //对象b包含一个成员对象:b.a成员对象由成员对象类的构造函数初始化:
- 如果在包含成员对象的类中,没有指出用成员对象类的什么构造函数对成员对象初始化,则调用成员对象类的默认构造函数。
- 可以在类构造函数的成员初始化表中显式指出用成员对象类的某个构造函数对成员对象初始化。
class A{ int x; public: A() { x = 0; } A(int i) { x = i; } }; class B{ A a; int y; public: B(int i) { y = i;} //调用A的默认构造函数对a初始化。 B(int i, int j): a(j) { y = i; } //调用A(int)对初始化。 }; B b1(1); //b1.y初始化为1,b1.a.x初始化为0 B b2(1,2); //b2.y初始化为1,b2.a.x初始化为2创建包含成员对象的类的对象时,先执行成员对象类的构造函数,再执行本身类的构造函数。
初始化成员对象时,若调用成员对象的非默认构造数,必用成员初始化列表
若成员初始化表为空,则调用成员对象的默认构造函数完成初始化
一个类若包含多个成员对象,这些对象的初始化次序按它们在类中的说明次序(而不是成员初始化表的次序)进行。
析构函数的执行次序与构造函数的执行次序正好相反。
- 先析构类对象,再析构成员对象
- 若有多个成员对象,则析构与构造次序相反
class Counter{
int val;
Public:
Counter(): val(0){cout<<“Defalut Constructor of Counter”<<endl;}
Counter(int x): val(x){cout<<“Constructor of Counter:”<<val<<endl;}
~Counter(){cout<<“Destructor of Counter:”<<val<<endl;}
};
class Example{
Counter c1, c2;
int val;
Public:
Example(): val(0){cout<<“Defalut Constructor of Example”<<endl;}
Example(int x): c2(x),val(x){cout<<“Constructor of Example:”<<val<<endl;}
~Example(){cout<<“Destructor of Example:”<<val<<endl;}
void Print() const {cout<<“value = ”<<val<<emdl;}
};
int main(){
Example e1, e2(4);
e2.Print();
return 0;
}
/*
Defalut Constructor of Counter
Defalut Constructor of Counter
Defalut Constructor of Example
Defalut Constructor of Counter
Constructor of Counter: 4
Constructor of Example: 4
value=4
Destructor of Example: 4
Destructor of Counter: 4
Destructor of Counter: 0
Destructor of Example: 0
Destructor of Counter: 0
Destructor of Counter: 0
*/# 4. 拷贝构造函数
- 在创建一个对象时,若用一个同类型的对象对其初始化,这时将会调用一个特殊的构造函数:拷贝构造函数。
class A{
......
public:
A(); //默认构造函数
A(const A& a); //拷贝构造函数 const可以省略,只是为了防止在函数体中修改实参对象
};
//此外拷贝构造函数还可如下:
A(const A& a, int i=0, int j=0);在三种情况下,会调用类的拷贝构造函数:
定义对象时,例如:
A a1; A a2(a1); //也可写成:A a2=a1; 或:A a2=A(a1); //调用A的拷贝构造函数,用对象a1初始化对象a2,把对象作为值参数传给函数时,例如:
void f(A x); A a; f(a); //调用f时将创建形参对象x,并调用A的拷贝构造函数,用对象a对其初始化。把对象作为函数的返回值时,例如:
A f(){ A a; ...... return a; //创建一个A类的临时对象,并调用A的拷贝构造函数,用对象a对其初始化。 }
//date.h
#include <iostream>
using namespace std;
class Date{
int year, month, day;
public:
Date(int y, int m, int d);
Date(int y=2000): year(y){
month = 4;
day=8;
cout<<"Constructor ofDate with 1 parameter."<<endl;
}
Date(const Date& d);
~Date(){cout<<"Destructor of Date: "<< year <<"."<< month <<"."<< day << endl;}
int IsLeapYear();
void Print(){cout<<year<<"."<<month<<"."<<day<<endl;}
};
//date.cpp
Date::Date(int y, int m, int d): year(y),month(m),day(d){
cout<<"Constructor of Date with 3 paramenters."<<endl;
}
Date::Date(const Date& d){
year=d.year;
month=d.month;
day=d.day;
cout<<"Copy constructor of Date"<<endl;
}
int Date::IsLeapYear(){
return (year%4==0 && year%100 !=0) || (year%400)==0;
}
Date fun(Date d){
Date temp; temp=d; return temp;
}
int main(){
Date date1(2000, 1, 1), date2(0, 0, 0);
Date date3(date1);
date2=fun(date3);
cout<<"date1: ";
date1.Print();
cout<<"date2: ";
date2.Print();
cout<<"date3: ";
date3.Print();
return 0;
}
/*
Constructor of Date with 3 parameters.
Constructor of Date with 3 parameters.
Copy constructor of Date. //date3(date1)
Copy constructor of Date. //d(date3) !!!!! 调用方法fun()时
Constructor of Date with 1 parameters. //(temp)
Copy constructor of Date.//匿名date2(temp)
Destructor of Date: 2000.1.1//temp对象
Destructor of Date: 2000.1.1 //d对象
Destructor of Date: 2000.1.1 //匿名对象
date1: 2000.1.1
date2: 2000.1.1
date3: 2000.1.1
Destructor of Date: 2000.1.1//date3对象
Destructor of Date: 2000.1.1//date2对象
Destructor of Date: 2000.1.1//date1对象
*/- 如果程序中没有为类提供拷贝构造函数,则编译器将会为其生成一个隐式拷贝构造函数。
- 隐式拷贝构造函数将逐个成员拷贝初始化:
- 对于普通成员:它采用通常的初始化操作;
- 对于成员对象:则调用成员对象类的拷贝构造函数来实现成员对象的初始化 。
class A{
int x,y;
public:
A() { x = y = 0; }
......
};
class B{
int z;
A a;
public:
B() { z = 0; }
...... //其中没有定义拷贝构造函数
};
...
B b1; //b1.z、b1.a.x以及b1.a.y均为0。
B b2(b1); //b2.z初始化成b1.z;调用A的拷贝构造函数用b1.a对b2.a初始化。如果A中没有定义拷贝构造函数,则A的隐式拷贝构造函数把b2.a.x和b2.a.y分别初始化成 b1.a.x和b1.a.y;否则,由A的自定义拷贝构造函数决定如何对b2.a.x和b2.a.y进行初始化。一般情况下,编译程序提供的默认拷贝构造函数的行为足以满足要求,类中不需要自定义拷贝构造函数。
在有些情况下必须要自定义拷贝构造函数,否则,将会产生设计者未意识到的严重的程序错误:
浅拷贝
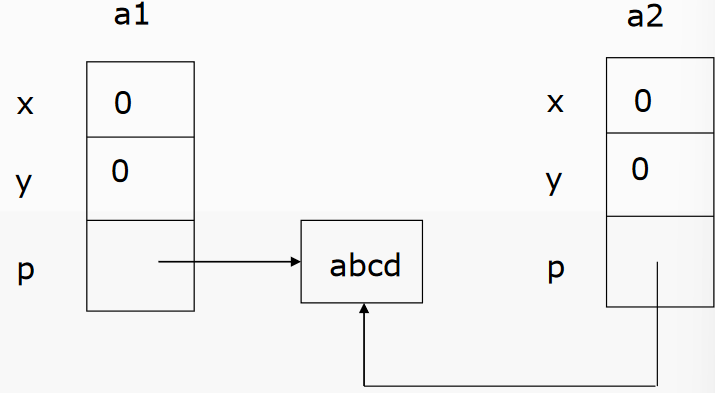
class A{ int x,y; char *p; public: A(char *str){ x = 0; y = 0; p = new char[strlen(str)+1]; strcpy(p,str); } ~A() { delete [] p; p=NULL; } }; ...... A a1(“abcd”); A a2(a1);![image-20230530140234188]()
系统提供的隐式拷贝构造函数将会使得 a1 和 a2 的成员指针 p 指向同一块内存区域!
- 如果对一个对象操作之后修改了这块空间的内容,则另一个对象将会受到影响。如果不是设计者特意所为,这将是一个隐藏的错误。
- 当对象 a1 和 a2 消亡时,将会分别去调用它们的析构函数,
这会使得同一块内存区域将被归还两次,从而导致程
序运行异常。
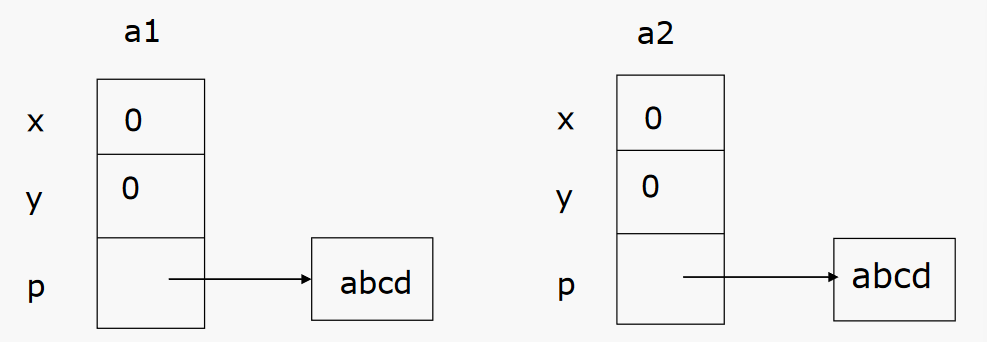
深拷贝
解决上面问题的办法是在类 A 中显式定义一个拷贝构造函数。
A::A(const A& a){ x = a.x; y = a.y; p = new char[strlen(a.p)+1]; strcpy(p,a.p); }![image-20230530140326030]()
隐式拷贝构造函数会调用成员对象的拷贝构造函数
自定义的拷贝构造函数将默认调用成员对象类的默认构造函数对成员对象初始化!
# (五) 进阶
# 1. 常 (const) 成员函数
# (1)常成员函数
为了防止在获取对象状态的成员函数中改变对象的状态,可以把它们说明成 **
const成员函数 **。声明与定义时都应加上
constclass Date{ public: void set(int y, int m, int d); //改变对象状态 int get_day() const; //获取对象状态 }; int Date::get_day() const {.....}const成员函数不能改变对象的状态(数据成员的值)。class A{ int x; char *p; public: ...... void f() const{ x = 10; //Error p = new char[20]; //Error strcpy(p,"ABCD"); //没有改变p的值,编译程序认为OK! } };给成员函数加上 const 修饰符还有一个作用:描述对常量对象所能进行的操作(常对象只能调用常成员函数)。
常成员函数不能调用非常成员函数。
const 成员函数可以修改 static 成员变量
✓ const 修饰 this 指针指向内容不可更改
✓ static 变量不用 this 指针访问const 成员函数不能修改对象的任何数据成员
# (2)常对象
使用 const 关键字修饰的对象称为常对象
<类名> const <对象名>或者const <类名> <对象名>常数据成员:
const说明的数据成员,只能通过构造函数的成员初始化列表显式进行初始化注意:
常对象在定义时必须进行初始化,而且不能被更新
常对象只能调用它的常成员函数
一般对象既可以调用常成员函数,也可以调用一般成员函数
对于成员函数,
const参与函数重载的区分常对象调用常成员函数,一般对象调用一般成员函数
常成员函数可以直接访问类的常数据成员及一般数据成员
# 2. 静态数据成员
# (1)静态数据成员
- 可通过静态数据成员来实现属于同一个类的不同对象之间的数据共享
- 类的静态数据成员对该类的所有对象只有一个拷贝。
- 往往在类的外部给出定义并进行初始化。在函数内部声明。
- 需要通过对象来访问。
a.x
# (2)静态成员函数
静态成员函数可以通过对象来访问外,也可以直接通过类来访问。
A::get_shared();或A a; a.get_shared();静态成员函数可以直接访问类的静态成员
静态成员函数不能直接访问类的非静态成员
静态成员函数没有隐藏的 this 参数
若要访问非静态成员,必须通过参数传递的方式得到相应的对象,再通过对象进行访问
class A{ int x,y; static int shared; public: A() { x = y = 0; } ...... static int get_shared(A& a) { return shared; } ...... int A::get_shared(A& a){ ......a.x......a.y }
# 3. 友元 (friend)
- 指定与一个类密切相关的、又不适合作为该类成员的程序实体(某些全局函数、某些其它类或某些其它类的某些成员函数)可以直接访问该类的 private 和 protected 成员。这些程序实体称为该类的友元。
class A{
......
friend void func(); //友元函数,可访问x
friend class B; //友元类,可访问x 类B中的所有成员函数都可以访问A类中的成员
friend void C::f(); //友元类成员函数,可访问x
private:
int x;
};- 友元关系具有不对称性,不具有传递性,友元关系不能被继承。
- 友元是数据保护和数据访问效率之间的一种折中方案。(破坏了类的封装性)
- 一个类的友元函数不属于这个类。
# 4. 转移构造函数
# 5. 操作符重载
# (1)概述
操作符重载实质上是函数重载
可以重载 C++ 中除下列操作符外的所有操作符:
成员选择符.,间接成员选择符.*->*,条件操作符?:,域解析符::,sizeof重载操作符时,其操作数中至少应该有一个是类、结构、枚举以及它们的引用类型。
操作符重载可通过下面两个途径来实现:
作为一个类的非静态的成员函数(
new和delete除外)。作为一个全局(友元)函数。
一般情况下,操作符既可以作为全局函数,也可以作为成员函数来重载。
在有些情况下,操作符只能作为全局函数或只能作为成员函数来重载。
# (2)双目操作符重载
① 作为成员函数重载
重载函数的声明格式
class <类名> { ...... <返回值类型> operator # (<类型>); //#代表可重载的操作符 };重载函数的定义格式
<返回值类型> <类名>::operator # (<类型> <参数>) { ...... }使用格式
<类名> a; <类型> b; a # b 或 a.operator#(b)
例:
class Complex{
double real, imag;
public:
......
bool operator ==(const Complex& x) const{
return (real == x.real) && (imag == x.imag);
}
bool operator !=(const Complex& x) const{
return (real != x.real) || (imag != x.imag);
}
};
......
Complex c1,c2;
......
if (c1 == c2) // 或 if (c1 != c2)
......② 作为全局(友元)函数重载
定义格式
<返回值类型> operator #(<类型1> <参数1>,<类型2> <参数2>) { ...... }使用格式:
<类型1> a; <类型2> b; a # b 或 operator#(a,b)
例:
class Complex{
double real, imag;
public:
Complex() { real = 0; imag = 0; }
Complex(double r, double i) { real = r; imag = i; }
......
friend Complex operator + (const Complex& c1,const Complex& c2);
friend Complex operator + (const Complex& c,double d);
friend Complex operator + (double d,const Complex& c);
};
Complex operator + (const Complex& c1,const Complex& c2){
return Complex(c1.real+c2.real,c1.imag+c2.imag);
}
Complex operator + (const Complex& c, double d){
return Complex(c.real+d,c.imag);
}
//只能作为全局函数重载,若使用成员函数不符合显式调用(操作符重载本质)
Complex operator + (double d, const Complex& c){
return Complex(d+c.real,c.imag);
}
......
Complex a(1,2),b(3,4),c1,c2,c3;
c1 = a + b;
c2 = b + 21.5;
c3 = 10.2 + a; 表达式 x=operator-(y,z) 还可以表示为 x=y-z
# (3)单目操作符重载
①作为成员函数重载
定义格式
class <类名> { ...... <返回值类型> operator # (); }; <返回值类型> <类名>::operator # () { ...... }使用格式
<类名> a; #a 或 a.operator#()
class Complex{
......
public:
......
Complex operator -() const{
Complex temp;
temp .real = -real;
temp.imag = -imag;
return temp;
}
};
......
Complex a(1,2),b;
b = -a; //把b修改成a的负数。②作为全局(友元)函数重载
定义格式
<返回值类型> operator #(<类型> <参数>) { ...... }使用格式
<类型> a; #a或operator#(a)
# 操作符 ++ 和 -- 的重载
操作符 ++(--)有前置和后置两种用法:
int x=0; ++x; x++; //OK ++(++x); (++x)++; //OK,++x为左值表达式 ++(x++); (x++)++; //Error,x++为右值表达式class Counter{ int value; public: Counter() { value = 0; } Counter& operator ++(){ //前置的++重载函数 value++; return *this; } const Counter operator ++(int){ //后置的++重载函数 Counter temp=*this; //保存原来的对象 value++; //写成:++(*this);更好!调用前置的++重载函数 return temp; //返回原来的对象 } }; Counter a,b,c; b = ++a; //使用的是上述类定义中不带参数的操作符++重载函数 c = a++; //使用的是上述类定义中带int型参数的操作符++重载函数 ++(++a); (++a)++; //OK ++(a++); (a++)++; //Error##### (4)特殊操作符的重载 ###### ①赋值操作符“=”的重载 - C++编译程序会为每个类定义一个隐式的赋值操作符重载函数,其行为是:逐个成员进行赋值操作 - 参照浅拷贝,解决上面问题的办法是自己定义赋值操作符重载函数 ```c++ class A{ ...... A& operator = (const A& a){//返回值应声明为引用 if (&a == this) return *this; //防止自身赋值。 delete []p;//如果被赋值对象占用了动态空间,应先释放,后接收 p = new char[strlen(a.p)+1]; strcpy(p,a.p); x = a.x; y = a.y; return *this; } };自定义的赋值操作符重载函数不会自动地去进行成员对象的赋值操作,必须要在自定义的赋值操作符重载函数中显式地指出。
赋值操作符只能作为非静态的成员函数来重载。
若使用全局函数,则会与隐式赋值操作符重载函数存在歧义
一般来讲,需要自定义拷贝构造函数的类通常也需要自定义赋值操作符重载函数。
# ②访问数组元素操作符 “[]” 的重载
- 对于由具有线性关系的元素所构成的对象,可通过重载 “[]”,实现对其元素的访问。
# ③重载操作符 new
操作符
new必须作为静态的成员函数来重载(static说明可以不写)void *operator new(size_t size);- 返回类型必须为
void * - 参数表示对象所需空间的大小,其类型为 size_t (unsigned int)
- new 重载函数可以有多个(参数需有所不同)
- 返回类型必须为
重载 new 时,除了对象空间大小参数以外,也可以带有其它参数
void *operator new(size_t size,XXX);使用格式:
p = new (XXX) A(...);
# ④重载操作符 delete
与重载操作符 new 相同
操作符 delete 也必须作为静态的成员函数来重载(
static说明可以不写)delete 重载函数只能有一个
# ⑤函数调用操作符 “()”
# ⑥类成员访问操作符 “->” 的重载
“->” 为一个双目操作符,其第一个操作数为一个指向类或结构的指针,第二个操作数为第一个操作数所指向的类或结构的成员。
通过对 “->” 进行重载,可以实现一种智能指针(smart pointers):
一个具有指针功能的对象,通过该对象访问所 “指向” 的另一个对象时,在访问所指向对象的成员前能做一些额外的事情。
智能指针 (smart pointer) 是存储指向动态分配(堆)对象指针的类,用于生存期控制,能够确保自动正确的销毁动态分配的对象,防止内存泄露(利用自动调用类的析构函数来释放内存)。
必用成员函数重载
# ⑦带一个参数的构造函数
- 带一个参数的构造函数可以用作从一个基本数据类型或其它类到某个类的转换。
class Complex{
double real, imag;
public:
Complex() { real = 0; imag = 0; }
Complex(double r) { real = r; imag = 0; }
Complex(double r, double i) { real = r; imag = i; }
......
friend Complex operator + (const Complex& x, const Complex& y);
};
......
Complex c1(1,2),c2,c3;
c2 = c1 + 1.7; //1.7隐式转换成一个复数对象Complex(1.7)
c3 = 2.5 + c2; //2.5隐式转换成一个复数对象Complex(2.5)# ⑧自定义类型转换
自定义类型转换,从一个类转换成基本数据类型或其它类(不需要返回值类型的声明)
class A{ int x,y; public: ...... operator int() { return x+y; } //类型转换操作符int的重载函数 }; ...... A a; int i=1; int z = i + a; //将调用类型转换操作符int的重载函数把对象a隐式转换成int型数据。
# 七、继承(类的复用)---- 派生类
# (一)概述
# 1. 继承关系
- 在继承关系中存在两个类:基类(或称父类)和派生类(或称子类)。
- 派生类拥有基类的所有特征,并可以
- 定义新的特征
- 或对基类的一些特征进行重定义。
# (二)单继承
单继承时,派生类只能有一个直接基类
# 1. 单继承派生类的定义:
- 定义:
class <派生类名>:[<继承方式>] <基类名>
{ <成员说明表>
};<继承方式> 指出对从基类继承来的成员的访问控制,可以是 public private protected
class A {//基类
int x,y;
public:
void f();
void g();
};
class B: public A {//派生类
int z; //新成员
public:
void h(); //新成员
};派生类除了拥有新定义的成员外,还拥有基类的所有成员(除了基类的构造 / 析构函数和赋值操作符重载函数)
定义派生类时一定要见到基类的定义。
如果在派生类中没有显式说明,基类的友元不是派生类的友元;如果基类是另一个类的友元,而该类没有显式说明,则派生类也不是该类的友元。
# 2. 访问基类成员
- 派生类不能直接访问基类的私有成员。
protected用它说明的成员不能通过对象使用,但可以在派生类中使用。
class A { //基类
int x,y;
public:
void f();
void g();
};派生类对基类成员的访问除了受到基类的访问控制的限制以外,还要受到标识符作用域的限制。
class B: public A{ int z; public: void f(); void h(){ f(); //B类中的f A::f(); //A类中的f } }; B b; b.f(); //B类中的f b.A::f(); //A类中的f即使派生类中定义了与基类同名但参数不同的成员函数,基类的同名函数在派生类的作用域中也是不直接可见的,可以用基类名受限方式来使用之
class B: public A{ int z; public: void f(int); //不是重载A的f! void h(){ f(1); //OK f(); //Error A::f(); //OK } }; ...... B b; b.f(1); //OK b.f(); //Error b.A::f(); //OK也可以在派生类中使用 using 声明把基类中某个的函数名对派生类开放
class B: public A{ int z; public: using A::f; void f(int); //不是重载A的f! void h(){ f(1); //OK f(); //OK,等价于A::f(); } }; ...... B b; b.f(1); //OK b.f(); //OK,等价于b.A::f();
# 3. 继承方式
- 默认的继承方式为:
private
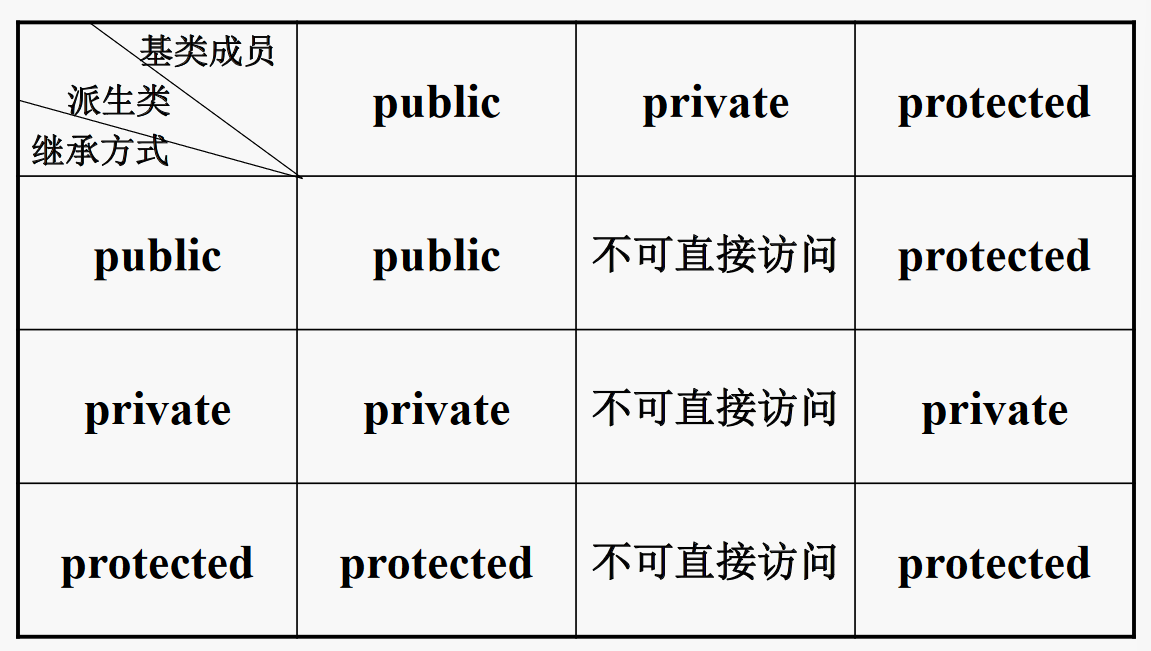
可在派生类中分别调整基类各成员的访问控制属性(基类 private 成员除外)
class A{ public: void f1(); protected: void g1(); }; class B: private A{ public: A::f1;//f1调整为public A::g1;//g1调整为public }可以将派生类对象赋值给基类对象
可以将派生类对象的地址赋值给基类指针
可以将派生类对象赋值给基类的引用
派生类对象不能赋值给派生类对象。
派生类指针变量不能指向基类对象。
派生类操作不能用于基类对象。
# 4. 初始化和赋值操作
# ①初始化
派生类构造函数必须负责调用基类构造函数,并对其所需要的参数进行设置
派生类对象的初始化由基类和派生类共同完成:
- 基类的数据成员由基类的构造函数初始化
- 派生类的数据成员由派生类的构造函数初始化
当创建派生类的对象时:
- 先执行基类的构造函数,再执行派生类构造函数。
- 默认情况下,调用基类的默认构造函数,如果要调用基类的非默认构造函数,则必须在派生类构造函数的成员初始化表中指出。
如果一个类 D 既有基类 B、又有成员对象类 M:
- 在创建 D 类对象时,构造函数的执行次序为:
B(调用顺序按照各个基类被继承时声明的顺序)->M->D 类构造函数体 - 当 D 类的对象消亡时,析构函数的执行次序为:D->M->B
- 在创建 D 类对象时,构造函数的执行次序为:
对于拷贝构造函数:
- 派生类的隐式拷贝构造函数(由编译程序提供)将会调用基类的拷贝构造函数。
- 派生类自定义的拷贝构造函数在默认情况下则调用基类的默认构造函数。需要时,可在派生类自定义拷贝构造函数的 “基类 / 成员初始化表” 中显式地指出调用基类的拷贝构造函数。
class A{
int a;
public:
A() { a = 0; }
A(const A& x) { a = x.a; }
......
};
class B: public A{
public:
B() { ...... }
...... //没有定义拷贝构造,需要时用隐式拷贝构造
};
class C: public A{
public:
C() {......}
C(const C& ) { ...... } //调用A的默认构造
......
};
class D: public A{
public:
D() {......}
D(const D& d): A(d) { ...... } //显式指定调用A的拷贝构造
......
};
B b1;//调用A()
B b2(b1); //调用A的拷贝构造
C c1;//调用A()
C c2(c1);//调用A的默认构造函数A()
D d1;//调用A()
D d2(d1);//调用A的拷贝构造# ②赋值
如果派生类没有提供赋值操作符重载,则系统会为它提供一个隐式的赋值操作符重载函数,其行为是:
- 对基类成员调用基类的赋值操作进行赋值,
- 对派生类的成员按逐个成员赋值。
派生类自定义的赋值操作符重载函数不会自动调用基类的赋值操作,需要显式地调用基类的赋值操作符来实现基类成员的赋值。
派生类不从基类继承赋值操作
class A{
......
};
class B: public A{
......
public:
B& operator =(const B& b){
if (&b == this) return *this; //防止自身赋值。
*(A*)this = b; //调用基类的赋值操作符对基类成员进行赋值。也可写成:this->A::operator =(b);
...... //对派生类的成员赋值
return *this;
}
};
......
B b1,b2;
b1 = b2;# ③聚集
- 继承不是代码复用的唯一方式,有些代码复用不宜用继承来实现。
- 类之间还存在一种聚集(aggregation,也称聚合)关系:
- 一个类作为另一个类的成员对象类。
- 具有聚集关系的两个类之间属于部分与整体的关系(is-a-part-of)
# ④子类型
- 子类型关系可以传递,但是不可逆
# (三)消息(成员函数调用)的动态绑定
class A{
int x,y;
public:
void f();
};
class B: public A{
int z;
public:
void f();
void g();
};
void func1(A& x){
......
x.f(); //调用A::f
......
}
void func2(A *p){
......
p->f(); //调用A::f
......
}
......
A a;
func1(a);
func2(&a);
B b;
func1(b);
func2(&b);# 1. 静态绑定
- 默认静态绑定
# 2. 动态绑定
- 一般情况下,需要在 func1(或 func2)中根据 x(或 p)实际引用(或指向)的对象来决定是调用
A::f还是B::f。即,采用动态绑定。在 C++ 中用虚函数来实现动态绑定。
class A{
int x,y;
public:
virtual void f(); //虚函数
};
class B: public A{
int z;
public:
void f();//仍为虚函数,在其派生类中可被再次重写
void g();
};
void func1(A& x){
......
x.f();
......
}
void func2(A *p){
......
p->f();
......
}
A a;
func1(a); //在func1中调用A::f
func2(&a); //在func2中调用A::f
B b;
func1(b); //在func1中调用B::f
func2(&b); //在func2中调用B::f基类中的一个成员函数如果被定义成虚函数,则在派生类中定义的、与之具有相同型构的成员函数是对基类该成员函数的重定义(或称覆盖,override)
相同的型构是指:派生类中定义的成员函数的名字、参数类型和个数与基类相应成员函数相同,其返回值类型与基类成员函数返回值类型或者相同,或者是基类成员函数返回值类型的派生类。
一旦在基类中指定某成员函数为虚函数,那么,不管在派生类中是否给出
virtual声明,派生类(以及派生类的派生类...)中与其有相同型构的成员函数均为虚函数。只有类的成员函数才可以是虚函数,但静态成员函数不能是虚函数。
构造函数不能是虚函数,析构函数可以(往往)是虚函数。
只有通过基类的指针或引用访问基类的虚函数时才进行动态绑定。
基类的构造函数中对虚函数的调用不进行动态绑定。
class A{
public:
A() { f();}
~A();
virtual void f();
void g();
void h() { f(); g(); }
};
class B: public A{
public:
~B();
void f();
void g();
};
......
A a; //调用A::A()和A::f
a.f(); //调用A::f
a.g(); //调用A::g
a.h(); //调用A::h、A::f和A::g
B b; //调用B::B(), A::A() 和 A::f !!!
b.f(); //调用B::f
b.g(); //调用B::g !!!!
b.h(); //调用A::h、B::f 和 A::g !!!
A *p;
p = &a;
p->f(); //调用A::f
p->g(); //调用A::g
p->h(); //调用A::h, A::f和A::g
p = &b;
p->f(); //调用B::f
p->A::f(); //调用A::f
p->g(); //调用A::g,对非虚函数的调用采用静态绑定。 !!!
p->h(); //调用A::h, B::f和A::g
p = new B; //调用B::B(), A::A()和A::f !!!
.......
delete p; //调用A::~A(),因为没有把A的析构函数定义为虚函数。 !!!# 3. 纯虚函数和抽象类
纯虚函数是指函数体为空(=0)的虚函数
class A{ ...... public: virtual int f()=0; //纯虚函数 ...... };包含纯虚函数的类称为抽象类
抽象类不能用于创建对象。
抽象类的作用是为派生类提供一个基本框架和一个公共的对外接口
# (四) 多继承
- 多继承是指派生类可以有一个以上的直接基类。
# 1. 定义
- 定义格式:
class <派生类名>: [<继承方式>] <基类名1>,[<继承方式>] <基类名2>,...
{
<成员说明表>
};- 继承方式及访问控制的规定同单继承。
- 派生类拥有所有基类的所有成员。
- 基类的声明次序决定:
- 对基类构造函数 / 析构函数的调用次序
- 对基类数据成员的存储安排。
class C: public A, public B
{
......
};
//构造函数的执行次序是:A()、B()、C()
//(A()和B()实际是在C()的成员初始化表中调用。)# 2. 命名冲突
- 解决方法:基类名受限
# 3. 重复继承 ---- 虚基类
若直接基类有公共的基类,则会出现重复继承
例:
class A { int x; ...... }; class B: public A { ... }; class C: public A { ... }; class D: public B, public C { ... }; //上面的类D将包含两个x成员:B::x和C::x虚基类
class B: virtual public A {...}; class C: virtual public A {...}; class D: public B, public C {...};对于包含虚基类的类:
- 虚基类的构造函数由最新派生出的类的构造函数调用。
- 虚基类的构造函数优先非虚基类的构造函数执行。
# 八、类属类型(泛型)---- 模板
# (一)模板

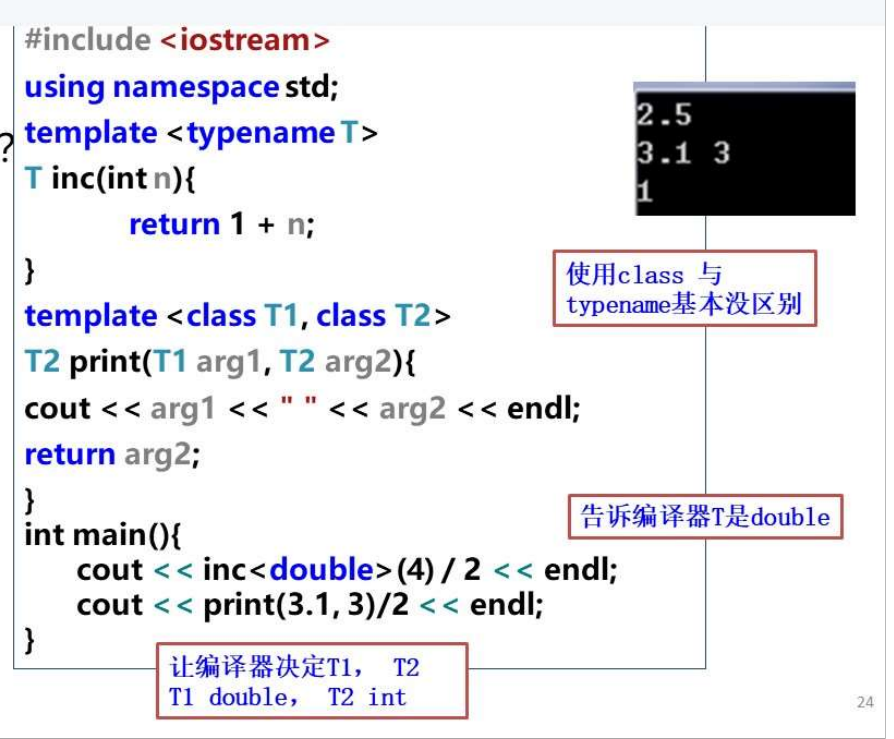
# (二)C++ 标准模板库(STL)
以下可忽略()
# N、库函数
# 1. 输入输出
#include <iomanip>
#include <iostream>
using namespace std;
int main(){
cout << "Hello, world!"; //输出
cout << endl; //换行
cout << "Rainnn!" << endl;
double root=5.33333;
cout << fixed << setprecision(2) << root;//保留两位小数
int i;
double d;
//输入
cin >> i;
cin >> d;
return 0;
}ios::sync_with_stdio(false); // 这两行能极大加速C++的输入性能。
cin.tie(nullptr); // 代价是不能混用scanf/printf。# 2. <cmath>
#include <cmath>
#include <iostream>
using namespace std;
int main(){
double count;
count = sqrt(double x); //求平方根
count = pow(double x,double y); //pow(底,指数的幂);
//三角函数
count = cos(double x);
count = sin(double x);
count = tan(double x);
count = acos(double x);
count = asin(double x);
count = atan(double x);
count = log(double x); //返回logex的值
count = log10(double x); //返回log10x的值
count = exp(double x); //返回指数函数e^x的值
count = exp2(double x); //指数函数e^x的值
count = hypot(3.0,4.0); //5.0 返回两个参数的平方总和的平方根,如果参数为一个直角三角形的两个直角边,函数会返回斜边的长度)
int c = abs(int x); //绝对值(只能填整数)
count = fabs(double x); //绝对值(可以填小数)
count = floor(5.89); //5 向下取整
count = ceil(5.89); //6 向上取整
count = max(5.0,4.0); //5.0 两者最大值
count = min(5.0,4.0); //4.0 两者最小值
}# 3. <bitset>
# (1) 进制 oct dec hex
#include <bitset>
#include<iostream>
using namespace std;
int main(){
int a;
cin >> hex >> a;//输入16进制数
cout << dec << a << endl;//转成10进制
cout << oct << 35<< endl; //转成8进制
cout << dec << 35 << endl; //转成10进制
cout << hex << 35 << endl; //转成16进制
cout << bitset<8>(35) << endl; //2进制 <8>:表示保留8位输出
return 0;
}# 4. 字符串
# (1) 基础
1.类似于使用数组
string a = “abcdef”;
int num = a.length();
for (int i = 0; i < num; ++i)
{
cout << a[i];
}
2.使用for循环
string a = “asdfa”;
for (char ch : a){
cout << ch;
}
cout << a.length();# (2) <string>
#include <string>
using namespace std;
int main(){
string s1, s2;
getline(cin, s1);//输入字符串
getline(cin, s2);
s1 += s2;//字符串拼接
s1.append(s2); //把字符串s连接到当前字符串的结尾
int num=10;
string to_string(num);//将数字转换为字符串,这里注意如果是浮点型数转字符,会将精度范围内小数点后的数全部显示出来
}1.int a = str.find_first_of('abc'); // 获取字符串中第一个指定字符(串)的位置
2.int a = str.find_last_of('.');// 获取字符串中最后一个指定字符(串)的位置
3.string str1 = str.substr(a,b);// 根据以上两个端位置,保留第a位及之后共b个字符,(若b超出size则到最后)stoi函数: 将string类型转换成int类型的函数
stod函数: 将string类型转换成double类型的函数
atof函数: 将string类型转换成double类型的函数# 5. <cctype>
1.isalpha(),用来判断一个字符是否为字母,如果是字符则返回非零,否则返回零。
2.isalnum(),用来判断一个字符是否为数字或者字母,也就是说判断一个字符是否属于a~z||A~Z||0~9。是返回非零,不是返回0。
3.islower(),用来判断一个字符是否为小写字母,也就是是否属于a~z。是返回非零,不是返回0。
4.isupper(),用来判断一个字符是否为大写字母。是返回非零,不是返回0。
if(isupper(str[i])){
...
}
5.char c = toupper(a),a为字符时,如果a是小写字母则将其转换为大写字母,否则不变。a为数字则将其按ASCLL码转换为对应字符。(其实即使a是字符,输入之后还是会将其转换为int类型)
6.char c = tolower(a),a为字符时,如果a是大写字母则将其转换为小写字母,否则不变。a为数字则将其按ASCLL码转换为对应字符。
7.isdigit(),用来判断一个字符是否为数字,如果是数字则返回非零,否则返回零。
8.int isxdigit( int c )(判断字符c是否:16进制数字)# 6. <sstream>
#include <sstream>
#include <iostream>
#include <sstream>
using namespace std;
int main(){
istringstream iss;
string s = "32 240 2 1450";
iss.str(s);
for (int n=0; n<4; n++){
int v;
iss >> v;
cout << v << endl;
}
cout << "Finished writing the numbers in: ";
cout << iss.str() << endl;
}
/*
32
240
2
1450
Finished writing the numbers in: 32 240 2 1450
*/#include <iostream>
#include <sstream>
using namespace std;
int main()
{
int i = 1000;
ostringstream ss;
ss << hex << i;
string result = ss.str();
cout << result << endl; // 3e8
return 0;
}# 7. <iomanip>
#include <iomanip>
cout << setw(3) << 1; //按3列宽度输出(默认右对齐)
cout << setw(3) << left << 1;//左对齐
cout << fixed << setprecision(2) << root;//保留两位小数# 8. <algorithm>
# (1) sort()
#include<iostream>
#include<algorithm>
using namespace std;
int main(){
int num[10] = {6,5,9,1,2,8,7,3,4,0};
sort(num,num+10,greater<int>());
for(int i=0;i<10;i++){
cout<<num[i]<<" ";
}//输出结果:9 8 7 6 5 4 3 2 1 0
return 0;
} 它有三个参数 sort(begin, end, cmp) ,其中 begin 为指向待 sort () 的数组的 第一个元素的指针 ,end 为指向待 sort () 的数组的 最后一个元素的下一个位置的指针 ,cmp 参数为排序准则,cmp 参数可以不写,如果不写的话,默认从小到大进行排序。如果我们想从大到小排序可以将 cmp 参数写为 greater<int>() 就是对 int 数组进行排序,当然 <> 中我们也可以写 double、long、float 等等。
自定义排序准则
#include<iostream> #include<algorithm> using namespace std; bool cmp(int x,int y){ return x % 10 > y % 10; } int main(){ int num[10] = {65,59,96,13,21,80,72,33,44,99}; sort(num,num+10,cmp); for(int i=0;i<10;i++){ cout<<num[i]<<" "; }//输出结果:59 99 96 65 44 13 33 72 21 80 return 0; }(也可以对结构体进行排序)
#include<iostream> #include<string> #include<algorithm> using namespace std; struct Student{ string name; int score; Student() {} Student(string n,int s):name(n),score(s) {} }; bool cmp_score(Student x,Student y){ return x.score > y.score; } int main(){ Student stu[3]; string n; int s; for(int i=0;i<3;i++){ cin>>n>>s; stu[i] = Student(n,s); } sort(stu,stu+3,cmp_score); for(int i=0;i<3;i++){ cout<<stu[i].name<<" "<<stu[i].score<<endl; } return 0; }
# 9. <regex>
# (1) regex_match
此函数模板用于匹配给定的模式。如果给定的表达式与字符串匹配,则此函数返回 true 。否则,该函数返回 false 。
# N+1、算法
# 1. 排序
# (1)冒泡排序
# (2)选择排序
#include <iostream>
using namespace std;
//从大到小
int main(){
int max,temp;
int n;
cin >> n;
int num[n];
for(int i=0;i<n;i++){
cin >> num[i];
}
for(int index=0;index<n-1;index++){
max=index;
for(int scan=index+1;scan<n;scan++){
if(num[scan]>num[max]){
max=scan;
}
}
temp=num[index];
num[index]=num[max];
num[max]=temp;
}
}
//从小到大
void sort(string str[],int n){
int min;
string temp;
for(int index=0;index<n-1;index++){
min=index;
for(int scan=index+1;scan<n;scan++){
if(str[scan].length()<str[min].length()){
min=scan;
}
}
temp=str[index];
str[index]=str[min];
str[min]=temp;
}
}